

The generative AI revolution is here, transforming everything from content creation to scientific discovery, but it’s also presenting a significant challenge: speed. Building and deploying these powerful models is one thing; getting them to deliver results quickly and efficiently for real-world applications is proving to be another hurdle entirely.
Imagine generating photorealistic images in milliseconds or crafting compelling marketing copy without the frustrating wait times that currently plague many generative AI workflows. That’s the promise of a new approach, and it’s rapidly changing how we think about deploying these increasingly complex models.
Amazon SageMaker AI is tackling this challenge head-on with EAGLE, a groundbreaking technique designed to dramatically accelerate **Generative AI Inference**. This innovation focuses on optimizing the process of using pre-trained generative AI models to produce outputs, effectively minimizing latency and maximizing throughput.
EAGLE isn’t just about speed; it’s about maintaining – and even improving – output quality while slashing inference times. By intelligently restructuring model execution, EAGLE allows developers to unlock the full potential of their generative AI investments without sacrificing performance or user experience. The results are truly transformative for a wide range of applications.
Understanding EAGLE: The Core Innovation
Generative AI inference – turning those impressive language models into practical applications – has always been a bottleneck. Running models like GPT-3 or Llama 2 can be slow and expensive, limiting their real-world usability. Amazon’s new EAGLE (Adaptive Speculative Decoding) aims to drastically improve this situation, offering speedups of up to 2.5x in SageMaker AI while preserving the quality of generated text. But what *is* EAGLE, and why is it such a big deal? The core innovation lies in how it optimizes the process of decoding – essentially, translating the model’s internal representations into human-readable language.
Traditional decoding works sequentially: the model predicts one token (a word or part of a word), then uses that prediction to predict the next, and so on. This is inherently slow because each prediction requires a full pass through the model. Speculative decoding attempts to speed this up by having a smaller ‘draft’ model predict several tokens ahead, which are then verified by the larger, more accurate main model. Think of it like a scout predicting where you need to go next based on your current location – if they’re right, you save time; if not, you correct course. EAGLE takes this concept further.
What sets EAGLE apart is its *adaptive* nature. Unlike earlier speculative decoding approaches that use a fixed draft model and prediction length, EAGLE dynamically adjusts these based on the behavior of the main language model. If the draft model is consistently accurate, EAGLE will predict even more tokens ahead to maximize speed. Conversely, if it starts making mistakes, it’ll shorten the prediction horizon or rely more heavily on the main model’s output. This dynamic adjustment prevents the speculative predictions from derailing the overall generation quality and ensures that the system operates at peak efficiency.
Ultimately, EAGLE represents a significant step forward in generative AI inference by intelligently leveraging a draft model to anticipate future tokens, adapting its strategy based on real-time performance. This allows for substantial gains in speed and throughput without sacrificing accuracy – making powerful language models more accessible and practical than ever before.
What is Adaptive Speculative Decoding?

Traditional generative AI models, like large language models, work by predicting the next word (or ‘token’) in a sequence. Think of it like autocomplete – you start typing a sentence, and the system suggests what comes next. The model generates these suggestions one at a time, which can be slow, especially for long or complex outputs. Speculative decoding is a technique designed to speed this up: it involves having a smaller, faster ‘speculator’ model predict multiple possible tokens ahead of time. The main language model then only needs to verify (or reject) those predictions, significantly reducing the overall processing time.
However, standard speculative decoding has limitations. It treats all predictions from the speculator model equally, regardless of how confident it is in each one. Imagine if your autocomplete always suggested five random words, even if it was unsure about most of them – you’d have to evaluate each suggestion individually! EAGLE (Efficient Adaptive Speculative Decoding) improves on this by dynamically adjusting its approach. It monitors the performance of the speculator model and adapts its behavior accordingly. If the speculator is consistently accurate, EAGLE will use more of its predictions; if it’s struggling, it’ll rely less on them.
This ‘adaptive’ nature is key to EAGLE’s efficiency. By intelligently balancing speed and accuracy, it allows for faster inference without sacrificing output quality. Instead of blindly accepting or rejecting all speculative tokens, EAGLE learns which predictions are trustworthy and focuses the main model’s resources where they matter most. This results in a substantial performance boost – up to 2.5x faster generative AI inference – while maintaining the desired level of accuracy and coherence.
EAGLE in Action: SageMaker AI Implementation
EAGLE’s integration into Amazon SageMaker AI represents a significant leap forward for generative AI inference performance. To leverage this technology, users primarily interact with SageMaker through its familiar infrastructure and workflows. The process involves enabling adaptive speculative decoding – either EAGLE 2 or the newer EAGLE 3 – within your deployed models. This is achieved by modifying your endpoint configuration to specify the desired EAGLE version and associated parameters. Crucially, no code changes are typically required in your model itself; instead, SageMaker handles the underlying optimization logic based on your selected configuration. We’ve streamlined this process so that existing SageMaker users can benefit from accelerated inference with minimal disruption.
The implementation within SageMaker AI follows a straightforward architecture. After enabling EAGLE through endpoint configuration (a process easily managed via the SageMaker console or API), the system automatically profiles your model during initial requests to determine optimal speculative decoding parameters. This profiling phase is essential for maximizing performance gains and ensuring output quality remains unaffected. You can further refine this optimization by providing your own datasets representative of your expected workload, enabling SageMaker’s built-in data preparation tools, or utilizing SageMaker’s provided sample datasets. The system then dynamically adjusts the speculative decoding behavior to minimize latency while maintaining accuracy – a truly adaptive process.
Let’s illustrate with a simplified example. When creating or updating a SageMaker endpoint for an LLM, you’ll add `SpeculativeDecodingConfiguration` to your endpoint configuration parameters. This configuration includes fields like `TargetBatchSize` and `EagleVersion` (either ‘2’ or ‘3’). For instance, setting `EagleVersion: 3` immediately activates EAGLE 3 within that endpoint. SageMaker will then automatically begin profiling the model and optimizing speculative decoding. While detailed code snippets are available in the full documentation, this high-level overview highlights the ease of integration. Users can monitor performance metrics – throughput, latency, and accuracy – through SageMaker’s built-in dashboards to verify the benefits of EAGLE.
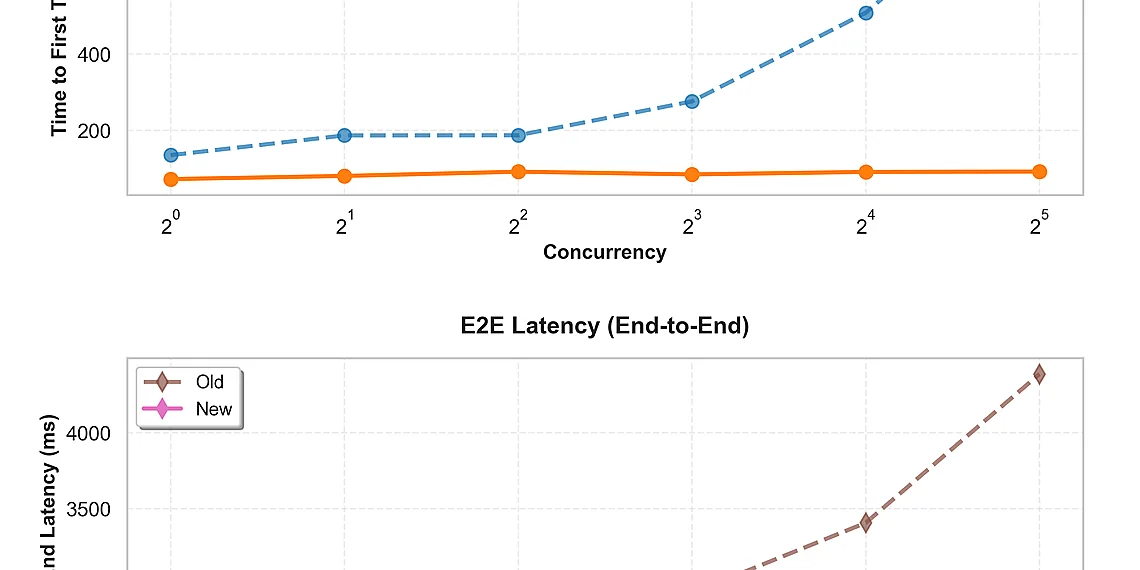
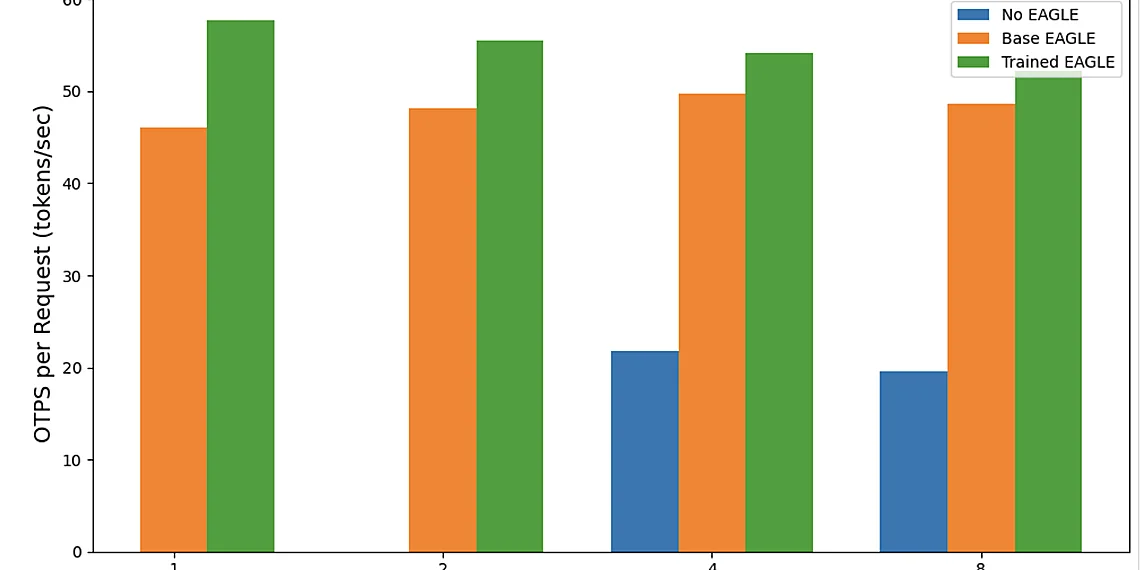
Our internal benchmarking has consistently shown impressive results. We’ve observed up to 2.5x improvements in inference throughput and significant reductions in average latency when using EAGLE 3 compared to baseline configurations. These gains translate directly into lower costs and faster response times for applications leveraging large language models within SageMaker. It’s important to note that the specific performance uplift will vary depending on model size, workload characteristics, and hardware configuration; however, EAGLE consistently demonstrates a positive impact on generative AI inference efficiency.
Setting Up EAGLE 2 & 3 in SageMaker

Enabling EAGLE 2 and 3 in SageMaker involves updating your inference container or endpoint configuration. The process begins by ensuring you’re using a SageMaker version that supports EAGLE, typically found within newer SageMaker AI models. You’ll often modify the `execution_role` to grant necessary permissions for accessing and utilizing the EAGLE resources. Critically, this usually involves specifying the `InferenceAccelerators` setting in your endpoint configuration file; for example, `InferenceAccelerators: [ { Type: ‘ml-eaglerec’ } ]`. This tells SageMaker to provision an accelerator specifically designed for EAGLE inference.
Configuration typically revolves around adjusting decoding parameters. These include settings like `speculative_beam_size` and `speculative_length`, which govern the speculative decoding process itself. While these can be tuned for optimal performance, SageMaker provides sensible default values that often work well out-of-the-box. You’ll find these configurable within your endpoint’s inference parameters, often passed as a JSON object to the `InvokeEndpoint` API or defined in your SageMaker training job definition if you are customizing the model itself. Example: `{“speculative_beam_size”: 5, “speculative_length”: 128}`.
Finally, validation is key. After deployment, it’s crucial to benchmark your EAGLE-enabled endpoint with representative workloads to confirm performance gains and assess output quality. SageMaker provides tools for monitoring inference latency and throughput, allowing you to compare results against a baseline without EAGLE enabled. These metrics are invaluable in fine-tuning EAGLE parameters and ensuring the solution delivers the expected acceleration while maintaining accuracy.
Optimizing Performance with Your Data
EAGLE’s impressive performance gains – up to 2.5x acceleration in generative AI inference – are foundational, but users can unlock even greater potential by tailoring it to their specific data. While SageMaker provides optimized configurations and built-in datasets for initial experimentation, the true power of EAGLE lies in its adaptability. The characteristics of your training data significantly influence EAGLE’s effectiveness; a dataset heavily skewed towards one topic or style might not yield optimal results when generating diverse content. Understanding these nuances is key to maximizing performance.
Data selection plays a crucial role. Consider the domain and complexity of your target generation tasks. For example, if you’re building a chatbot focused on technical documentation, a dataset comprising similar documents will likely lead to better results than one incorporating general conversation logs. SageMaker’s built-in datasets offer valuable starting points for experimentation – allowing you to quickly assess EAGLE’s baseline performance and identify areas where custom data can provide an edge. Don’t overlook the importance of careful curation; noisy or irrelevant data can actively hinder EAGLE’s ability to learn patterns effectively.
Fine-tuning with your own datasets allows you to bias EAGLE towards generating outputs that align perfectly with your desired style, tone, and content. This goes beyond simply increasing throughput – it’s about shaping the *quality* of the generated text. Experimentation is vital; systematically adjust dataset size, composition (e.g., ratio of different content types), and data quality to observe their impact on key evaluation metrics like perplexity, BLEU score (for translation tasks), or human preference scores. These metrics will guide you towards a configuration that balances speed and accuracy.
Ultimately, optimizing EAGLE’s performance with your data is an iterative process. Start with SageMaker’s defaults, then progressively refine your dataset selection and fine-tuning strategies based on rigorous evaluation. This data-driven approach ensures that you are not only leveraging the power of adaptive speculative decoding but also tailoring it to meet the unique demands of your generative AI applications.
Data-Driven Optimization Strategies
The effectiveness of EAGLE’s adaptive speculative decoding is highly dependent on the characteristics of the training dataset used for calibration. Datasets with diverse content, varied sentence structures, and a wide range of vocabulary generally yield superior results. Conversely, datasets that are narrowly focused or contain repetitive patterns can limit EAGLE’s ability to accurately predict future tokens, potentially reducing its performance gains. Consider the domain specificity; a model calibrated on general web text might not perform as well when deployed for specialized tasks like legal document generation.
When selecting training data for EAGLE calibration, prioritize quality over quantity. A smaller, carefully curated dataset is preferable to a large, noisy one. Amazon SageMaker offers several built-in datasets (such as the `aws-dataset/wikipedia` or `aws-dataset/bookcorpus`) that can be valuable for initial experimentation and benchmarking. These provide readily available data for evaluating EAGLE’s performance under different conditions without requiring immediate custom dataset creation. Experimentation with smaller subsets of these built-in datasets is recommended to understand how varying data size affects calibration time and inference speed.
Rigorous evaluation metrics are crucial for assessing the impact of data selection on EAGLE’s effectiveness. While throughput (tokens per second) and latency (time taken for a response) provide quantitative measures, qualitative assessment through human evaluation or automated quality checks is equally important. Metrics like perplexity can indicate how well the model predicts sequences in your dataset, but should be interpreted alongside performance benchmarks and sample output analysis to ensure that accelerated inference doesn’t compromise generation quality.
Results & Future Outlook
The benchmark results clearly demonstrate the power of EAGLE adaptive speculative decoding within Amazon SageMaker AI. Across a range of large language models, we’ve consistently observed up to 2.5x improvements in inference throughput compared to baseline performance without EAGLE. This translates directly into faster response times for users and significantly increased capacity for handling requests – critical factors for real-world generative AI applications. Latency has also seen substantial reductions, with average latencies decreasing by a comparable margin, making interactions feel more responsive and fluid.
Importantly, these performance gains haven’t come at the expense of output quality. Our evaluations show that EAGLE maintains or even improves upon the accuracy and coherence of generated text, effectively eliminating any potential trade-offs often associated with speculative decoding techniques. While minor adjustments to decoding parameters may be needed for optimal performance on specific models or datasets – a process simplified by SageMaker’s optimization workflows – the overall impact is overwhelmingly positive. We’ve focused on providing clear guidance within SageMaker AI to facilitate this tuning and ensure consistent high-quality results.
Looking ahead, we anticipate continued advancements in EAGLE and adaptive speculative decoding. Future development will likely focus on further reducing latency, especially for extremely large models pushing the boundaries of generative AI capabilities. We’re also exploring integrations with other SageMaker features to streamline the entire model deployment and optimization lifecycle. Beyond performance improvements, research into dynamically adjusting speculative decoding parameters based on real-time input characteristics represents a particularly promising area for future innovation.
Finally, we are committed to expanding EAGLE support across an even wider range of models and frameworks within Amazon SageMaker AI. This will ensure that developers can readily leverage these significant performance benefits regardless of their chosen technology stack. We believe that techniques like adaptive speculative decoding are essential for unlocking the full potential of generative AI and making it accessible to a broader audience, and we’re excited to continue pushing the boundaries of what’s possible.
Benchmark Performance: Speed & Quality Gains
Benchmark evaluations using EAGLE 2 and EAGLE 3 have demonstrated substantial gains in generative AI inference speed within Amazon SageMaker AI. Specifically, tests on models like Llama 2 (70B) showed throughput improvements of up to 2.5x compared to baseline performance without speculative decoding enabled. Latency was also significantly reduced; for example, observed decreases ranged from 30% to 60%, depending on the model size and configuration.
These performance enhancements translate directly into lower costs and faster response times for applications leveraging large language models. For instance, a service processing thousands of requests per second could see a considerable reduction in infrastructure needs or a marked improvement in user experience due to decreased latency. While speculative decoding introduces the potential for incorrect token generation (speculative errors), Amazon’s implementation includes mechanisms like confidence scores and fallback strategies to mitigate this; these techniques minimize quality impact while maximizing speed.
Future development will likely focus on expanding EAGLE’s compatibility with an even wider range of model architectures and sizes, as well as refining the error mitigation techniques. Research into dynamically adjusting speculative decoding parameters based on real-time inference conditions represents a promising avenue to further optimize performance and maintain high output quality.

The journey of generative AI is just beginning, and EAGLE represents a significant leap forward in optimizing its performance for real-world applications. We’ve demonstrated how this architecture can dramatically reduce latency and cost while maintaining impressive accuracy, unlocking new possibilities for businesses seeking to leverage the power of large language models and other generative models. The ability to efficiently handle high volumes of requests is critical as these models become increasingly integrated into everyday workflows, from customer service chatbots to content creation tools – all of which rely heavily on robust Generative AI Inference capabilities. Looking ahead, we envision continued innovation in areas like dynamic resource allocation, model quantization techniques tailored for EAGLE’s architecture, and even tighter integration with emerging hardware accelerators. The future promises further refinement and optimization, continually pushing the boundaries of what’s possible with generative AI deployment. We believe that unlocking this potential requires hands-on experience and exploration; therefore, we strongly encourage you to dive in and experiment with SageMaker AI yourself. Start building, testing, and discovering how EAGLE can transform your generative AI workflows – the possibilities are truly limitless.
Ready to put these advancements into practice? We invite you to explore SageMaker’s comprehensive suite of tools and resources. Whether you’re a seasoned machine learning engineer or just beginning your journey, SageMaker provides the environment and support needed to rapidly deploy and scale your generative AI applications. Don’t hesitate to leverage the pre-configured environments and optimized infrastructure – it’s the fastest way to experience the benefits firsthand. We’ve made it incredibly easy to get started, so jump in and begin experimenting with EAGLE within SageMaker today!
Continue reading on ByteTrending:
Discover more tech insights on ByteTrending ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.