

The relentless flow of goods across continents fuels modern economies, yet orchestrating that movement is an incredibly intricate challenge. Supply chains are increasingly global and demanding, requiring unprecedented efficiency to minimize costs and maximize throughput. At the heart of this complex system lies a critical operation often overlooked: container stowage planning (CSPP). This process dictates how shipping containers are arranged within a vessel’s hold or on deck, directly impacting fuel consumption, port turnaround times, and overall operational effectiveness.
For decades, CSPP has relied heavily on human expertise – experienced planners meticulously arranging containers based on intricate rules and historical data. While invaluable, this approach struggles to scale with the ever-increasing volume of cargo and complexity of modern vessels; it’s also susceptible to subjective biases and limitations in exploring truly optimal configurations. The consequences of suboptimal stowage can ripple through the entire supply chain, leading to costly delays and reduced profitability.
Fortunately, a new wave of artificial intelligence offers a compelling alternative. Deep reinforcement learning (RL), with its ability to learn complex strategies through trial and error, is emerging as a powerful tool for tackling CSPP. This approach allows algorithms to discover efficient stowage plans without explicit programming or reliance on pre-defined rules. Our recent study dives deep into this exciting intersection of AI and container logistics, providing a crucial benchmark comparison of several leading RL algorithms designed specifically for optimizing container stowage.
We’ve rigorously tested these methods against established industry standards, offering valuable insights into their strengths and weaknesses. This analysis aims to accelerate the adoption of RL-driven solutions within the field and pave the way for more resilient, efficient, and data-driven supply chains.
Understanding Container Stowage Planning
Container stowage planning (CSPP) might sound like a niche topic, but it’s actually a vital piece of the global supply chain puzzle. Simply put, CSPP involves figuring out the most efficient way to arrange shipping containers on a vessel or within a container terminal. Think about it: ships are massive and need to be loaded in a way that ensures stability, prevents damage to the cargo, and allows for quick unloading at different ports. Traditionally, this process has heavily relied on human expertise – experienced planners meticulously arranging containers based on years of intuition and rule-of-thumb practices. While these experts do an admirable job, their decisions are inherently subjective and can be slow, especially as container ships grow in size and complexity.
The challenges inherent in CSPP make it notoriously difficult to optimize. There’s a complex web of constraints to consider: weight distribution must be balanced to prevent instability; certain containers might require refrigeration or specific handling; other containers need to be readily accessible for unloading at particular ports. On top of these physical limitations, there are operational objectives, such as minimizing crane movement and maximizing the number of containers loaded per unit time. Finding a solution that satisfies all these constraints while simultaneously achieving those objectives is an incredibly complex combinatorial problem – essentially, it’s like solving a giant, three-dimensional puzzle with constantly shifting requirements.
Because CSPP involves so many variables and conflicting goals, traditional optimization techniques often struggle to find truly optimal solutions within reasonable timeframes. Manual planning is labor-intensive and prone to human error; simpler algorithms might provide improvements but fall short of capturing the full complexity. This is where a newer approach – reinforcement learning (RL) – offers significant promise. RL allows an algorithm to learn through trial and error, adapting its strategies based on rewards and penalties within a simulated environment. Unlike traditional methods that require explicit programming for every scenario, RL can potentially discover novel and highly effective stowage plans without being explicitly told how.
The inherent difficulty of CSPP – the vast number of possible configurations, the conflicting constraints, and the need for real-time adaptability – makes it an ideal candidate for tackling with reinforcement learning. By framing the problem as a series of decisions within a dynamic environment, RL algorithms can explore different strategies and learn to optimize container stowage in ways that would be challenging or impossible for human planners or traditional optimization methods alone.
The Complexity of Stacking Containers

Container stowage planning (CSPP) is a vital but challenging task in both maritime shipping and port terminal operations. Essentially, it involves figuring out the optimal arrangement of shipping containers on a vessel or within a container terminal. These aren’t just randomly stacked boxes; each container has specific characteristics – weight, size, type (e.g., refrigerated), and destination – that must be carefully considered to ensure safe and efficient loading and unloading. A poorly planned stowage can lead to delays, increased fuel consumption, damage to cargo, and even safety hazards.
Traditionally, CSPP relies heavily on the expertise of human planners who use a combination of rules-of-thumb, experience, and specialized software tools. These planners balance competing objectives: maximizing vessel utilization (fitting as many containers as possible), maintaining stability during transit, minimizing container rehandling (moving containers multiple times), and accommodating port operational constraints like crane capacity and sequencing. However, the complexity of these factors makes finding truly optimal solutions incredibly difficult; human planners are often limited by cognitive biases and time pressures.
The problem’s inherent complexity arises from the sheer number of variables involved – modern container ships can carry thousands of containers – and the intricate interplay between them. Even seemingly minor decisions about placement can have cascading effects on other aspects of the operation. This makes CSPP a prime candidate for optimization techniques like reinforcement learning, which are designed to tackle complex decision-making problems where finding an analytical solution is impractical.
Reinforcement Learning Tackles the Problem
Container stowage planning (CSPP), a vital process within maritime transportation and terminal operations, has historically depended heavily on human expertise due to its inherent complexity. Traditional methods often struggle with the combinatorial explosion of possibilities when arranging containers onboard ships or within terminals – finding the optimal solution that maximizes space utilization while adhering to strict constraints like weight distribution and container compatibility is an incredibly challenging task. These limitations can lead to inefficiencies in loading/unloading, increased turnaround times, and ultimately higher operational costs.
Enter reinforcement learning (RL), a powerful branch of artificial intelligence that offers a promising alternative. Unlike traditional algorithms that rely on predefined rules or heuristics, RL allows an ‘agent’ – in this case, our CSPP optimizer – to learn through trial and error within an ‘environment’. This environment represents the ship’s hold or terminal layout. The agent takes actions (placing containers), receives feedback in the form of ‘rewards’ for good placements (efficient space use, meeting constraints) and ‘penalties’ for violations (weight imbalances, incompatible container pairings). Think of it like teaching a dog tricks; positive reinforcement encourages desired behavior.
The core beauty of RL lies in its ability to adapt and improve over time. The agent iteratively refines its strategy based on these rewards and penalties, gradually learning the optimal policy – the best sequence of actions to maximize cumulative reward. This contrasts sharply with traditional CSPP approaches which often get stuck in local optima or require extensive manual adjustments to accommodate changing conditions. By framing container logistics as a sequential decision-making problem, RL can explore a much wider range of solutions and potentially uncover arrangements previously unseen by human planners.
To facilitate research and comparison within the field, researchers have developed benchmark environments – essentially simulated CSPP scenarios – allowing for systematic evaluation of different RL algorithms. This new work introduces such an environment incorporating crane scheduling, enabling testing across a spectrum of complexity levels using techniques like DQN, QR-DQN, A2C, PPO, and TRPO. The results promise to shed light on the strengths and weaknesses of these approaches when applied to the demanding problem of container logistics.
How RL Approaches Container Optimization

Container stowage planning (CSPP), the process of determining optimal placement of containers within a ship or terminal, presents significant challenges due to the vast number of possible arrangements and complex constraints like weight distribution, container compatibility, and sequence requirements. Traditional methods often rely on heuristics and manual adjustments, struggling to consistently achieve truly optimized solutions and frequently requiring substantial human intervention – a factor highlighted earlier as a limitation in efficiency and scalability.
Reinforcement learning (RL) offers a promising alternative by framing CSPP as an agent interacting with an environment. In this context, the ‘agent’ is the RL algorithm itself, tasked with finding the best container placement strategy. The ‘environment’ represents the ship or terminal layout, including existing containers and constraints. Through repeated trial and error, the agent learns which actions (placing a specific container in a particular location) lead to desirable outcomes.
The learning process is driven by a reward system. Efficient arrangements – those minimizing movement distances, maximizing space utilization, and satisfying all constraints – earn positive rewards. Conversely, violating constraints like exceeding weight limits or placing incompatible containers together results in penalties. Over time, the agent adjusts its strategy to maximize cumulative rewards, effectively discovering optimized container placement policies without explicit programming for every possible scenario.
The Benchmark Study: Algorithms Compared
To rigorously evaluate deep reinforcement learning (DRL) approaches for container logistics, we constructed a custom Gym environment designed to mirror the intricacies of Container Stowage Planning Problems (CSPPs). This environment incorporates key elements such as container characteristics (weight, size, type), bay constraints, and crane movement limitations. Crucially, we extended this base environment to include crane scheduling considerations, implementing both single-agent (a centralized controller managing all cranes) and multi-agent (each crane controlled independently) setups. This allowed us to test the algorithms’ adaptability across different operational models commonly found in modern terminals.
Our benchmark study assessed five prominent DRL algorithms: Deep Q-Network (DQN), QR-DQN (a variant addressing DQN’s instability), Advantage Actor-Critic (A2C), Proximal Policy Optimization (PPO), and Trust Region Policy Optimization (TRPO). We systematically varied the problem complexity by adjusting factors such as the number of containers, bay dimensions, and the degree of constraint tightness. This controlled ramp-up in difficulty enabled us to observe how each algorithm scaled with increasing operational demands, providing valuable insights into their robustness and efficiency within the context of container logistics.
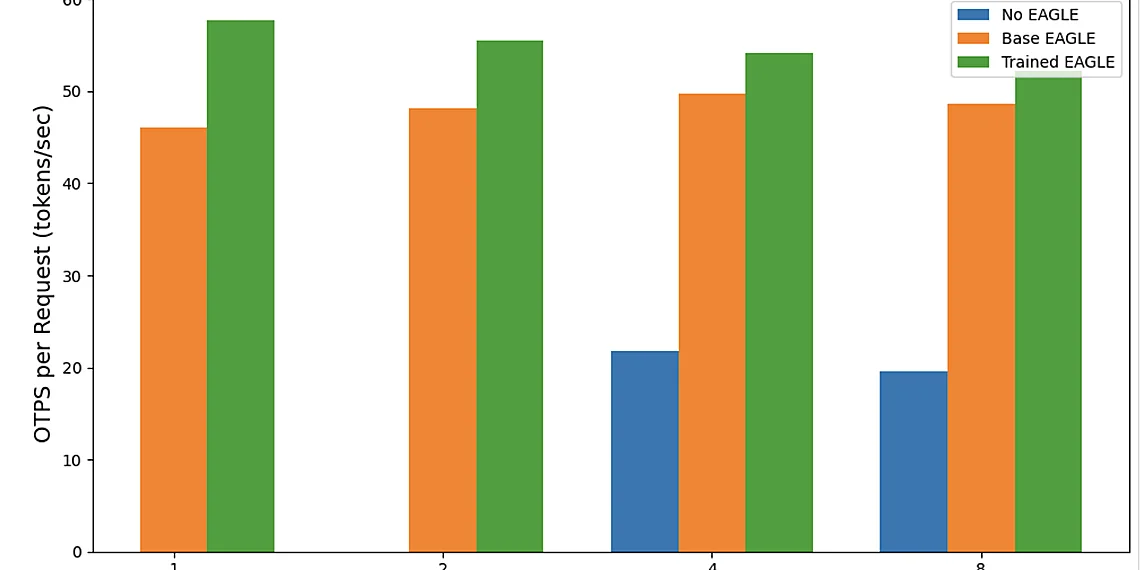
The results demonstrated a clear divergence in performance across algorithms based on complexity level. While DQN showed initial promise for simpler scenarios, its instability became apparent as the problem size increased. QR-DQN offered improvements over standard DQN but still struggled with highly constrained environments. A2C and PPO consistently outperformed these earlier methods, showcasing better convergence and more efficient exploration of the solution space. Notably, TRPO exhibited the most robust performance across all tested complexity levels, although at a higher computational cost. This highlights the trade-off between algorithmic efficiency and solution quality – no single algorithm universally excels.
Ultimately, our benchmark study underscores that selecting the optimal DRL algorithm for container logistics is highly context-dependent. The ‘best’ choice hinges on factors such as the scale of operations, available computing resources, and the level of constraint tightness inherent in the planning problem. These findings emphasize the need for tailored solutions rather than a one-size-fits-all approach when implementing DRL to optimize terminal efficiency.
Performance Under Pressure: Algorithm Strengths & Weaknesses
The benchmark study employed a custom-built OpenAI Gym environment designed to simulate container logistics challenges, specifically focusing on Container Stowage Planning Problems (CSPPs). This environment allows for controlled experimentation with varying levels of complexity, achieved by adjusting factors like the number of containers, vessel size, and crane constraints. Five prominent deep reinforcement learning (DRL) algorithms – Deep Q-Network (DQN), QR-DQN, Advantage Actor-Critic (A2C), Proximal Policy Optimization (PPO), and Trust Region Policy Optimization (TRPO) – were evaluated within this framework, both in single-agent and multi-agent configurations to model crane scheduling.
Findings revealed that no single algorithm consistently outperformed all others across all complexity scenarios. DQN and QR-DQN struggled with higher container volumes and tighter constraints, demonstrating limitations in handling the increased state space and action selection challenges. A2C generally showed good initial performance but often plateaued earlier compared to PPO and TRPO. PPO and TRPO proved more robust at scaling to larger problem sizes, exhibiting better long-term learning capabilities and adapting effectively to complex crane scheduling requirements; however, they also exhibited higher computational demands during training.
The study’s overall conclusion emphasizes that selecting an appropriate DRL algorithm for container logistics is highly context-dependent. While PPO and TRPO appear promising for tackling the most demanding scenarios, their resource intensity necessitates careful consideration. The results highlight the trade-offs between solution quality, training time, and computational cost, underscoring the need for tailored solutions rather than a universally applicable approach.
Future Directions & Practical Implications
The implications of applying deep reinforcement learning to container logistics are far-reaching, promising significant efficiency gains and cost reductions across the maritime industry. Currently, stowage planning – a crucial element in ensuring ships load and unload efficiently – often depends heavily on human expertise, which can be slow and prone to sub-optimal solutions. By automating this process with RL algorithms like DQN, PPO, and TRPO (as demonstrated by our benchmark studies), we open the door to dramatically faster loading times, reduced fuel consumption through optimized ship balancing, and minimized port congestion – all contributing to a leaner, more responsive supply chain.
Looking ahead, several exciting research avenues build upon this foundation. Future work should focus on incorporating dynamic constraints that realistically reflect the complexities of port operations; factors like unexpected weather changes, fluctuating cargo volumes, or equipment malfunctions are currently simplified in many models. Expanding the scope beyond static stowage plans to incorporate real-time crane scheduling optimization is also critical – coordinating multiple cranes efficiently can unlock substantial additional benefits. Furthermore, investigating hierarchical reinforcement learning approaches could allow for more nuanced control and adaptation to varying operational conditions.
A key enabler of this continued progress is the open-source Gym environment we’ve developed. This standardized platform allows researchers and practitioners alike to easily replicate our experiments, build upon our work, and contribute new algorithms and scenarios. By providing a common ground for comparison, it accelerates innovation within the field and fosters collaboration towards solving the challenges inherent in container logistics optimization.
Ultimately, the successful deployment of RL-driven solutions requires careful consideration of real-world implementation factors such as data availability, computational resources, and integration with existing terminal operating systems. While this research represents a significant step forward, bridging the gap between simulated environments and practical application will be vital to realizing the full potential of deep reinforcement learning in transforming container logistics.
Beyond the Benchmark: What’s Next?
While current deep reinforcement learning (DRL) approaches offer promising solutions for container stowage planning (CSPP), significant opportunities remain to expand their capabilities and address real-world complexities. Future work should focus on integrating crane scheduling optimization directly into the DRL framework, moving beyond simply considering container placement. This integrated approach would enable more efficient yard utilization and reduce overall handling time, leading to substantial operational gains in port terminals.
Furthermore, current CSPP models often operate under static assumptions. Incorporating dynamic constraints – such as fluctuating vessel arrival times, unexpected equipment failures, or changing weather conditions – will be crucial for robust real-world deployment. Research should explore techniques like recurrent neural networks (RNNs) or other temporal modeling approaches to allow DRL agents to adapt to these unpredictable factors and maintain optimal performance.
The newly developed Gym environment is a vital catalyst for accelerating innovation in this field. Its open-source nature encourages broader participation from researchers, allowing for rapid experimentation with new algorithms and scenarios. This collaborative development will be instrumental in addressing the remaining challenges of CSPP and ultimately driving widespread adoption of DRL solutions within the container logistics industry, resulting in improved efficiency and cost reductions.
Our investigation has demonstrated a clear path forward for leveraging deep reinforcement learning in optimizing complex operational challenges within container logistics.
The results consistently show that RL agents, when properly trained and configured, can outperform traditional rule-based systems in scenarios involving resource allocation, route optimization, and even dynamic port congestion mitigation. This represents a significant leap towards more efficient and resilient supply chains – imagine the impact on global trade!
While this study provides compelling evidence of RL’s potential, it also highlights areas ripe for further exploration; factors like real-time data integration, multi-agent coordination across disparate stakeholders, and robust handling of unforeseen disruptions remain crucial research targets.
The complexities inherent in container logistics demand a continuous cycle of innovation and refinement. To accelerate this progress, we’ve released our experimental environment as an open-source Gym setting – allowing others to build upon our work and explore new algorithmic approaches. This collaborative effort will be vital for pushing the boundaries of what’s possible with AI-driven optimization in this critical sector. We invite you to dive into the code, experiment with different strategies, and contribute your insights to shape the future of intelligent logistics systems. Let’s build a smarter, more connected world together – check out the Gym environment details linked below!
Continue reading on ByteTrending:
Discover more tech insights on ByteTrending ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









