

Amazon Bedrock is a fully managed service providing access to high-performing foundation models (FMs) from various AI leaders through a unified API. This enables organizations to build generative AI applications with enhanced security, privacy, and responsible AI practices. Learn more about Bedrock.
Batch inference in Amazon Bedrock is specifically designed for scenarios involving large datasets where immediate responses aren’t essential. Notably, it offers a 50% cost reduction compared to on-demand inference, making it an exceptionally efficient choice for processing extensive data using Bedrock foundation models. As organizations increasingly leverage Bedrock for large-scale data analysis, implementing robust monitoring and management is critical for optimizing performance and ensuring reliability.
This article details how to implement automated monitoring for Amazon Bedrock batch inference jobs using serverless AWS services like Lambda, DynamoDB, and EventBridge. This approach minimizes operational overhead while providing real-time visibility into job status and results. We’ll illustrate this with a practical example from the financial sector – building a production-ready system that tracks job progress, delivers timely notifications, and maintains comprehensive audit records for your bedrock jobs.
Understanding the Business Challenge: A Financial Services Use Case
Consider a financial services company handling millions of customer interactions and data points—credit histories, spending habits, and financial preferences. They aim to personalize product recommendations at scale using advanced AI techniques. While real-time responses aren’t always necessary or cost-effective for this task, analyzing such vast datasets requires careful planning and robust monitoring solutions. Furthermore, ensuring the accuracy and reliability of these recommendations is paramount in a regulated industry like finance.
The Need for Batch Inference
Real-time inference may not be suitable due to latency constraints or cost considerations when dealing with large volumes of data. For example, generating personalized financial product suggestions for millions of customers would significantly strain real-time resources and increase costs. Therefore, batch inference allows the company to process these recommendations efficiently in a non-interactive manner.
The Importance of Monitoring
Without proper monitoring, identifying issues with bedrock batch jobs—such as errors during processing or unexpected delays—becomes challenging. This can lead to inaccurate recommendations and potential financial losses for customers. Automated monitoring provides the visibility needed to proactively address these concerns and maintain a high level of service.
Architecting an Automated Monitoring Solution
The proposed solution leverages Amazon Bedrock batch inference alongside automated monitoring, utilizing a serverless architecture for efficiency and scalability. Here’s a breakdown of how it works:
- Customer credit data and product details are initially uploaded to an Amazon S3 bucket.
- A Lambda function retrieves the prompt template and data from S3, constructing a JSONL file containing prompts for each customer along with their relevant credit data and available financial products. This JSONL format is ideal for batch inference workloads within Bedrock.
- The same Lambda function then initiates an Amazon Bedrock batch inference job using this generated JSONL file. The prompt template often includes role instructions to guide the FM’s response; for instance, instructing it to act as a financial advisor.
- An EventBridge rule continuously monitors the state changes of the bedrock batch inference job. When the job completes or encounters an error, this rule triggers another Lambda function.
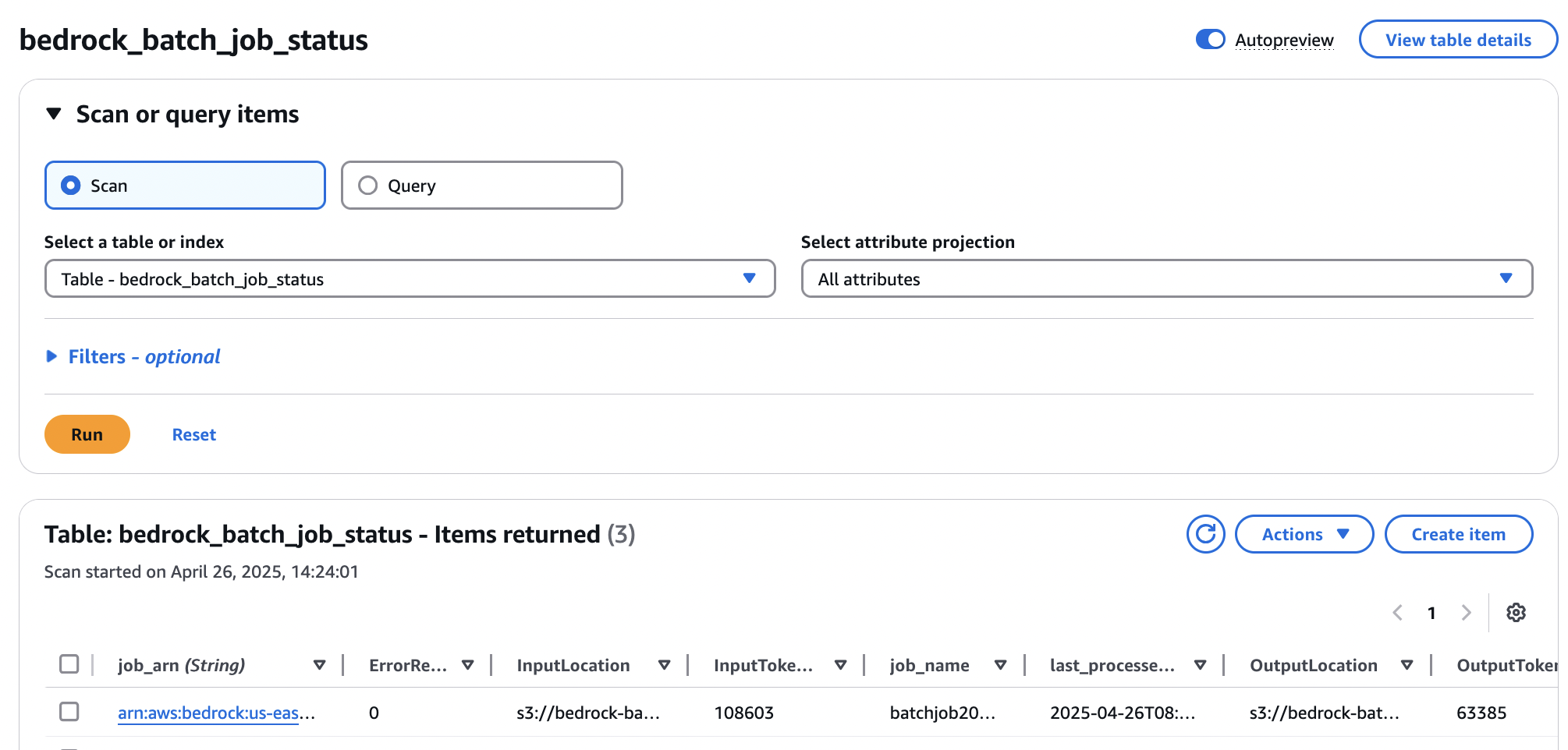
- The second Lambda function records the job status and results in Amazon DynamoDB for auditing and reporting purposes, providing a historical record of processing activities. This detailed logging is crucial for troubleshooting and compliance.
Benefits and Key Considerations
Automated monitoring offers significant advantages when working with bedrock batch inference jobs.
- Real-Time Visibility: Provides immediate insight into job status, duration, and potential errors – enabling quick identification of problems.
- Proactive Issue Detection: Allows for early detection and resolution of issues before they impact downstream processes or user experience.
- Improved Efficiency: Reduces manual intervention by automating monitoring tasks and optimizing resource utilization.
- Enhanced Auditability: Maintains a complete record of processing activities, crucial for compliance and regulatory requirements.
Furthermore, this architecture is highly scalable and cost-effective due to the use of serverless services. However, it’s important to consider factors like data security, access control, and error handling when implementing such a system. Properly configuring these aspects ensures both efficiency and reliability in your bedrock workflows.
In conclusion, automated monitoring for Amazon Bedrock batch inference jobs is essential for optimizing performance, ensuring reliability, and maintaining compliance within organizations leveraging foundation models at scale. By implementing the solution described here, businesses can unlock the full potential of bedrock while minimizing operational overhead and maximizing efficiency.
Source: Read the original article here.
Discover more tech insights on ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









