Inside the Challenge: The Rise of Incomplete Sensor Data
Wearable sensor technology is exploding. From fitness trackers to medical monitoring devices, we’re collecting an unprecedented amount of data about human movement and physiology. However, this data isn’t always perfect. Sensors can be noisy, prone to dropouts, or simply provide incomplete readings due to factors like user motion, environmental interference, or device limitations. This ‘incomplete sensor data’ presents a significant challenge for many applications – how do we reliably extract meaningful insights when the information is fragmented? The core issue revolves around ensuring reliable data streams and understanding their limitations, particularly in increasingly complex IoT environments.
Introducing LSM-2: A Generative AI Approach
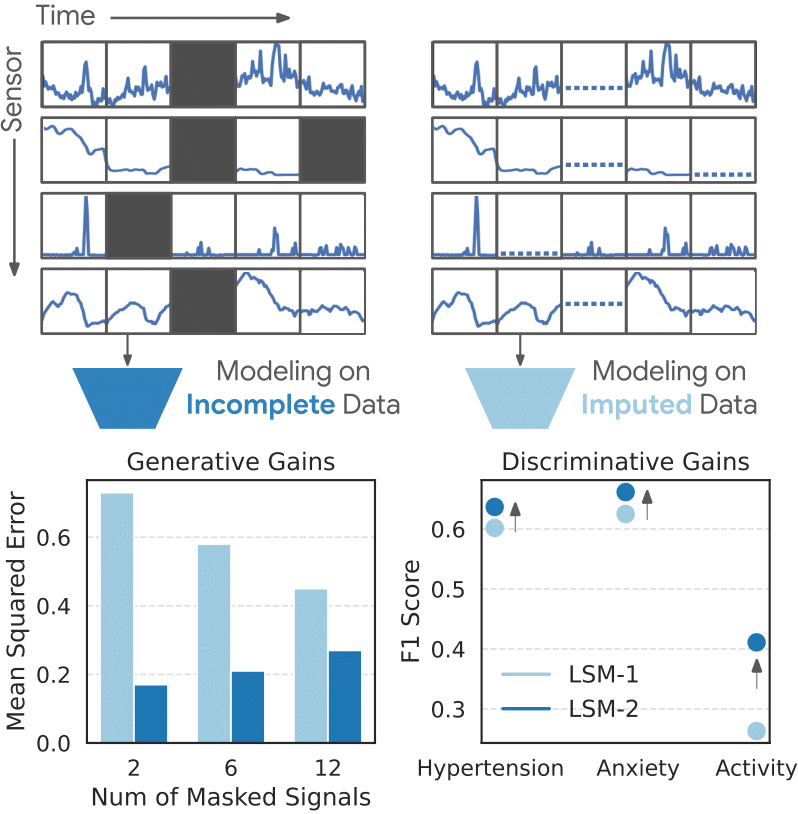
The Google Research team tackled this problem head-on with LSM-2 (Learning from Sparse Multi-Sensor Data), a novel approach leveraging generative AI. Their research, detailed in a recent blog post, focuses on training models to generate plausible sensor data when observations are missing. Instead of simply discarding incomplete readings, LSM-2 learns the underlying patterns and distributions of sensor data and then uses this knowledge to fill in the gaps – essentially creating a ‘best guess’ based on what it has learned. This approach directly addresses the challenge of data scarcity and unreliable measurements.
Key Innovations:
- Generative Models: LSM-2 employs generative adversarial networks (GANs) to create realistic synthetic data. The generator attempts to produce plausible sensor readings, while the discriminator tries to distinguish between real and generated data. This competitive process forces the generator to learn the nuances of the sensor data distribution. The use of GANs is a sophisticated technique for dealing with missing information by learning complex dependencies.
- Multi-Sensor Fusion: The system doesn’t rely on a single sensor type; it integrates information from multiple sensors (e.g., accelerometer, gyroscope) to improve the accuracy of the generated readings. Combining diverse data streams provides a richer context for understanding movement patterns. Integrating multiple sources mitigates the impact of individual sensor failures or inaccuracies.
- Sparse Training: LSM-2 is trained using a sparse dataset – meaning that only a fraction of the complete sensor data is used during training. This forces the model to learn robust representations that can generalize effectively even with missing information. This efficient training method is crucial for scalability and reducing computational costs.
How It Works: A Practical Example
Imagine a wearable device tracking a user’s walking speed. The accelerometer might occasionally lose signal due to sudden movements or changes in orientation. With LSM-2, the system wouldn’t just ignore these gaps. Instead, it would analyze the available data (e.g., previous steps, direction of travel) and generate plausible readings for the missing intervals – effectively ‘filling in’ the gaps in the walking speed timeline. This allows for more complete tracking profiles even when data is intermittent.
Benefits of this Approach:
- Improved Accuracy: By generating realistic sensor data, LSM-2 can significantly improve the accuracy of downstream analysis tasks, such as activity recognition or fall detection. Accurate insights are paramount in many applications where decisions rely on precise sensor data.
- Robustness to Noise: The generative model is inherently robust to noisy sensor readings because it learns to ‘smooth out’ inconsistencies. This resilience makes the system more reliable under real-world conditions.
- Data Efficiency: Training with sparse data reduces the need for massive amounts of labeled sensor data, which can be expensive and time-consuming to collect. This is a significant advantage in resource-constrained environments.
Looking Ahead: Applications and Future Research
The LSM-2 approach has broad implications across various applications. It could be used to improve the reliability of fitness trackers, enhance medical monitoring systems, or even enable more accurate human activity recognition in smart cities. Further research will focus on developing more sophisticated generative models, exploring new sensor fusion techniques, and adapting LSM-2 to different types of wearable devices and data streams. This work represents a crucial step towards harnessing the full potential of incomplete sensor data – transforming what was once a limitation into an opportunity for innovation. Continued development in this area is vital as IoT deployments become increasingly widespread.


Source: Read the original article here.
Discover more tech insights on ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









