

- Fine-tune OpenAI’s GPT-OSS models using Amazon SageMaker HyperPod recipes to unlock advanced capabilities with multilingual reasoning. This post, the second installment in our GPT-OSS series, provides a practical guide on customizing these foundational models for enhanced performance and scalability. Part 1 demonstrated fine-tuning with open source Hugging Face libraries via SageMaker training jobs – leveraging distributed multi-GPU and multi-node configurations to spin up high-performance clusters on demand. Now, we delve into utilizing SageMaker HyperPod recipes to streamline this process further.
The core of the solution lies in leveraging SageMaker HyperPod’s pre-built, validated configurations. These recipes dramatically reduce the complexity associated with setting up distributed training environments, offering enterprise-grade performance and scalability for large models. We’ll explore a hands-on example fine-tuning the GPT-OSS model on a multilingual reasoning dataset – specifically, HuggingFaceH4/Multilingual-Thinking – enabling it to handle structured, chain-of-thought (CoT) reasoning across multiple languages.
Solution Overview:
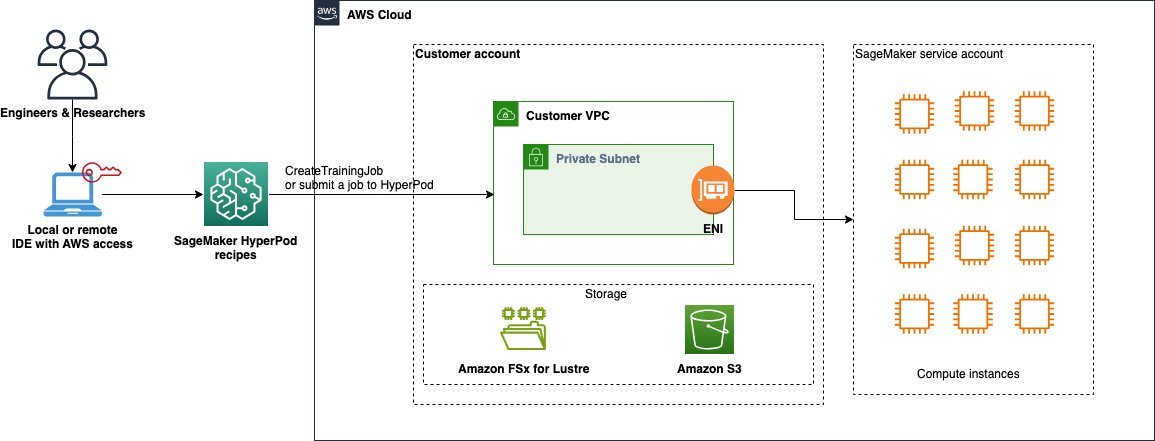
The proposed solution utilizes SageMaker HyperPod recipes and Training Jobs for efficient fine-tuning. Recipes are orchestrated through the SageMaker HyperPod recipe launcher, which manages job launches on architectures like SageMaker HyperPod (using Slurm or Amazon EKS) or training jobs. This approach provides a simplified entry point into distributed training, abstracting away much of the underlying infrastructure management. The image representing a complex system – a river flowing through mountains – represents a complex system – a river flowing through mountains. This aligns with the idea of training and optimizing large models, suggesting scale and intricate processes.
Prerequisites: To successfully follow this guide, you’ll need to have the following in place:
* AWS credentials configured for accessing SageMaker resources.
* A local or remote development environment.
* Familiarity with basic machine learning concepts and Hugging Face libraries.
Data Preparation: The process begins with preparing your dataset – in this case, the HuggingFaceH4/Multilingual-Thinking dataset. This data is then persisted to either Amazon FSx for Lustre (ideal for high-performance I/O) or Amazon S3 (for simpler storage). The prepared data serves as the foundation for training your customized GPT-OSS model. The chess board image clearly represents strategic thinking and problem-solving – concepts often associated with machine learning and model training. The visual connection to a complex system is strong.
Fine-tuning and Deployment: The recipe launcher orchestrates the fine-tuning job, leveraging the chosen architecture – HyperPod or Training Jobs – to efficiently process the data. Once the fine-tuning is complete, the resulting model is deployed to a SageMaker endpoint for testing, evaluation, and real-world application. This approach provides a simplified entry point into distributed training, abstracting away much of the underlying infrastructure management. For detailed instructions on fine-tuning the GPT-OSS model, refer to our comprehensive guide: Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face libraries. This guide provides step-by-step instructions and best practices for optimizing your fine-tuning process.
To truly unlock the potential of GPT-OSS, consider experimenting with different training parameters – batch size, learning rate, epochs – to achieve optimal performance for your specific use case. Careful tuning can lead to significant improvements in accuracy and efficiency. Furthermore, exploring techniques like data augmentation can expand your dataset and enhance model robustness. The key is iterative experimentation and thorough evaluation.
Source: Read the original article here.
Discover more tech insights on ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









