Categorical Belief Propagation: A New Era for AI Inference
Unlock faster, more reliable AI! A novel approach to inference using categorical belief propagation overcomes limitations of previous methods & ...
Read moreDetailsUnlock faster, more reliable AI! A novel approach to inference using categorical belief propagation overcomes limitations of previous methods & ...
Read moreDetailsUnlock maximum value from your LLMs! Discover ROI-Reasoning, a groundbreaking framework for AI inference optimization that dynamically adjusts resources & ...
Read moreDetailsDiscover how Meaning-First Execution (MFEE) revolutionizes transformer inference! Learn to optimize AI models by skipping unnecessary computations, boosting efficiency & ...
Read moreDetailsUnlock greater flexibility in tackling uncertainty! A novel approach called factor abstraction is revolutionizing probabilistic programming by separating model design ...
Read moreDetailsStruggling with slow, resource-intensive AI inference efficiency? Discover Thermodynamic Focusing (ICFA), a new approach inspired by physics that intelligently directs ...
Read moreDetailsUnlock faster, more efficient large language models! CodeGEMM tackles a key bottleneck in quantized LLMs - dequantization - streamlining matrix ...
Read moreDetailsDiscover how LLM temperature scaling enhances reasoning in large language models. This technique refines output quality and accuracy during inference ...
Read moreDetailsDiscover how **test-time scaling** is revolutionizing AI! Learn how dynamically allocating computing power during inference enhances large language models' reasoning ...
Read moreDetailsTired of high costs from LLM usage? Discover how **LLM inference caching** slashes expenses and boosts performance by storing & ...
Read moreDetailsReduce costs & speed up your LLM applications with LMCache! This innovative solution uses **LLM inference caching** to store & ...
Read moreDetailsLMCache boosts LLM inference with efficient KV caching, offering up to 15x throughput improvements & streamlining enterprise AI deployments. Explore ...
Read moreDetailsSpeed up your AI models! Discover how an **inference cache** can dramatically reduce latency and costs by intelligently reusing previous ...
Read moreDetailsExplore how reducing model size with techniques like **quantization** can boost performance & efficiency without sacrificing accuracy. Learn practical strategies ...
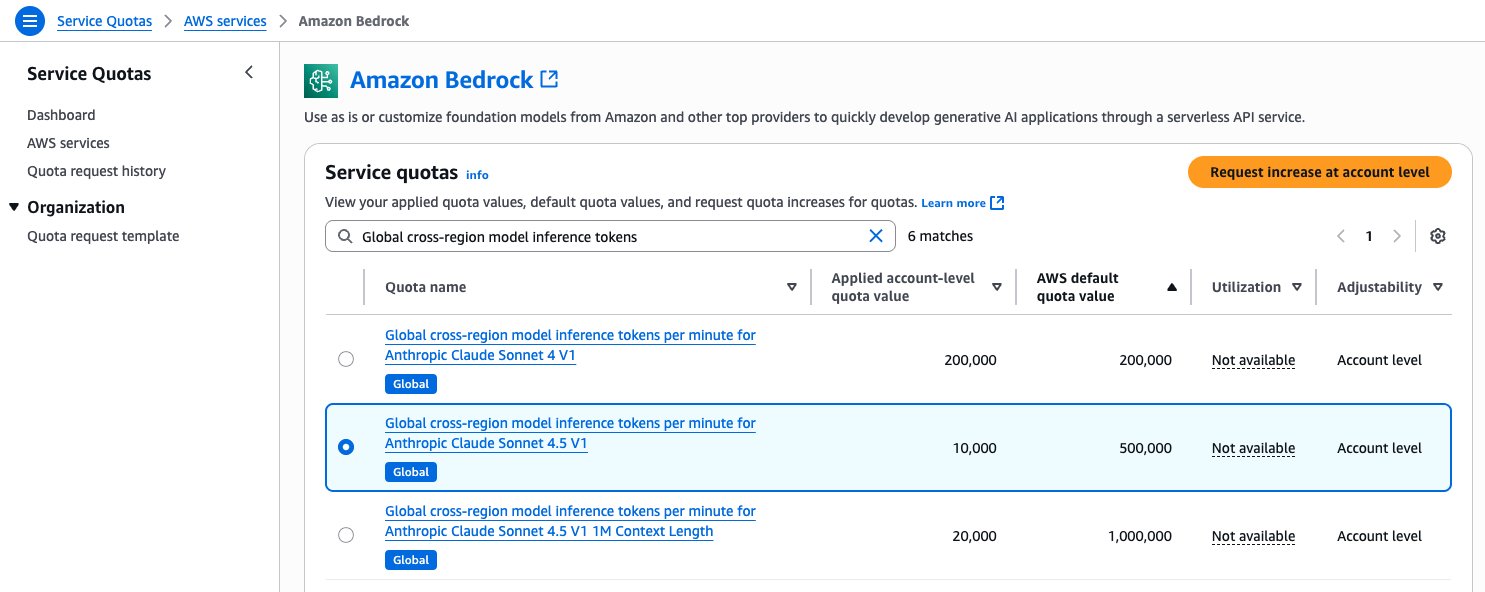
Read moreDetailsScale your AI workloads globally with Amazon Bedrock's new cross-Region inference, now available with Anthropic’s Claude Sonnet 4.5.
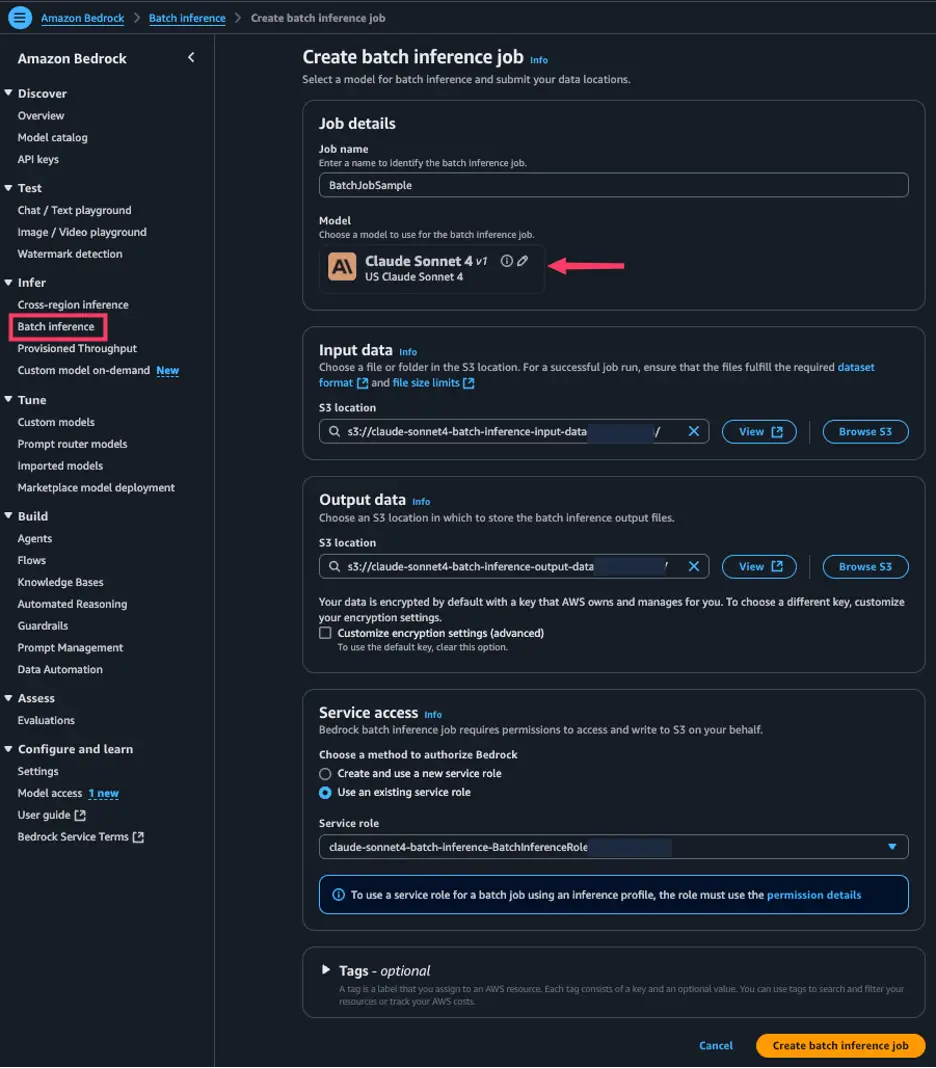
Read moreDetailsLearn how to monitor and manage Amazon Bedrock batch inference jobs using CloudWatch metrics & dashboards for optimized performance, cost ...
Read moreDetailsGoogle's Speculative Cascades speeds up LLM inference by 3x using a hybrid approach of speculative decoding & cascaded verification. Learn ...
Read moreDetailsBy aligning model serving with Kubernetes-native tooling, Gateway API Inference Extension aims to simplify and standardize how AI/ML traffic is ...
Read moreDetailsByteTrending is your hub for technology, gaming, science, and digital culture, bringing readers the latest news, insights, and stories that matter. Our goal is to deliver engaging, accessible, and trustworthy content that keeps you informed and inspired. From groundbreaking innovations to everyday trends, we connect curious minds with the ideas shaping the future, ensuring you stay ahead in a fast-moving digital world.
Read more »