

The rise of generative AI has unleashed a wave of exciting possibilities, but deploying individual models often falls short of addressing complex, real-world challenges., Many intricate tasks demand more than just one AI—they require coordinated effort from multiple agents working in concert., This is where the concept of multi-agent systems truly shines, promising to unlock unprecedented levels of automation and problem-solving capabilities., At Amazon, we’ve seen firsthand how crucial it is to move beyond isolated models and embrace a strategic approach to AI agent orchestration., Our journey scaling these systems has revealed that achieving true impact isn’t just about building intelligent agents; it’s about expertly fine-tuning their interactions and workflows—a process that yields remarkable improvements in efficiency, accuracy, and overall performance., We’re excited to share insights into our experiences and the techniques we’ve developed to maximize the potential of AI agent orchestration for real-world applications.
The initial promise of individual generative models has largely been realized, but tackling increasingly sophisticated tasks necessitates a paradigm shift in how we deploy these powerful tools., Imagine an autonomous system capable of not just generating text or images, but also planning, executing, and adapting across multiple steps—that’s the power unlocked by multi-agent systems., The complexity inherent in coordinating numerous agents demands a robust framework for AI agent orchestration, ensuring seamless communication and task delegation., We’ve found that applying advanced fine-tuning techniques to these orchestrated workflows is essential for achieving consistent results and unlocking significant performance gains, allowing us to tackle challenges previously deemed insurmountable.
The Rise of Multi-Agent Orchestration
The concept of an AI agent – a software entity capable of perceiving its environment and taking actions to achieve specific goals – has moved beyond theoretical discussions and into practical application across numerous industries. These agents, often powered by large language models (LLMs), are increasingly being deployed for tasks ranging from customer service chatbots to automated code generation. While individual agents can be highly effective in narrow domains, the true power emerges when they’re combined and coordinated – a practice known as AI agent orchestration.
AI Agent Orchestration refers to the process of managing and coordinating multiple AI agents working together towards a common objective. Think of it like directing an orchestra: each instrument (agent) plays its part beautifully individually, but only under a conductor’s guidance do they create harmonious and complex music. In the realm of AI, this orchestration allows for tackling significantly more intricate problems than any single agent could handle alone. For example, instead of one agent attempting to diagnose a medical condition and recommend treatment, an orchestrated system might involve agents specializing in symptom analysis, lab result interpretation, literature review, and patient history assessment – all contributing to a comprehensive diagnosis.
The growing adoption of AI agent orchestration is fueled by the recognition that real-world challenges are rarely simple. They often require diverse skills, knowledge domains, and decision-making capabilities. Single-agent systems struggle with complexity, prone to errors or inefficient solutions. Orchestration provides adaptability, resilience (if one agent fails, others can compensate), and scalability – vital for enterprise-level deployments. However, this approach isn’t without its challenges. Coordinating multiple agents introduces complexities in communication protocols, conflict resolution, ensuring consistency across different agent behaviors, and maintaining overall system stability.
Furthermore, effectively orchestrating AI agents necessitates robust monitoring and debugging capabilities. Tracking individual agent performance and identifying bottlenecks within the orchestrated workflow can be difficult. The rise of specialized frameworks and platforms designed for AI Agent Orchestration is a direct response to these challenges, aiming to simplify development, deployment, and management while unlocking the full potential of collaborative AI systems.
What are AI Agents?

At their core, AI agents are autonomous entities designed to perceive their environment and take actions to achieve specific goals. Think of them as digital workers – they can range from simple chatbots responding to customer inquiries to sophisticated systems managing complex supply chains. Unlike traditional software programs which require explicit instructions for every step, AI agents leverage machine learning models, particularly large language models (LLMs), to make decisions and adapt their behavior based on feedback and changing circumstances.
These agents play a crucial role in automation and problem-solving across various industries. They can automate repetitive tasks like data entry or report generation, freeing up human employees for more strategic work. More complex applications involve using AI agents to diagnose medical conditions, personalize educational experiences, or even design new products. Their ability to learn and improve over time makes them powerful tools for addressing dynamic challenges that would be difficult or impossible for humans to handle alone.
The rise of multi-agent orchestration—coordinating multiple AI agents working together—is further amplifying their capabilities. Imagine a team of specialized agents, each responsible for a different aspect of a project, collaborating seamlessly to achieve a shared objective. This approach allows organizations to tackle even more intricate problems and unlock new levels of efficiency and innovation.
Why Orchestration Matters

Single AI agents, while impressive in isolation, often struggle when faced with complex, real-world tasks that require diverse skills and adaptability. These agents frequently hit limitations related to reasoning capacity, knowledge boundaries, and the ability to handle unexpected situations or edge cases. For instance, a single agent designed for customer service might excel at answering FAQs but falter when confronted with a nuanced complaint requiring coordination across multiple departments – a scenario common in many businesses.
AI Agent Orchestration addresses these limitations by combining multiple specialized agents that work together towards a shared goal. This approach allows for the distribution of workload, leveraging each agent’s strengths to overcome individual weaknesses. Imagine an orchestration system where one agent handles initial data gathering, another analyzes the information, and a third generates a response – this collaborative structure dramatically expands the scope and reliability of AI’s ability to tackle intricate problems.
The increasing adoption of multi-agent systems is driven by the need for scalable and robust solutions in areas like robotic process automation, content creation, and advanced customer support. However, effective orchestration isn’t without its challenges; these include designing clear communication protocols between agents, managing dependencies and potential conflicts, and ensuring overall system stability as complexity increases.
Fine-Tuning Techniques: From Basics to Breakthroughs
Fine-tuning is the cornerstone of transforming general-purpose large language models (LLMs) into specialized AI agents capable of tackling real-world challenges. Amazon has extensively leveraged this process across various divisions, achieving remarkable results like a 33% reduction in dangerous medication errors within its Pharmacy division and an impressive 80% reduction in engineering effort at Global Engineering Services. The journey from foundational fine-tuning methods to advanced techniques represents a constant push for improved accuracy, efficiency, and alignment with human values – all crucial elements when deploying AI agents at scale.
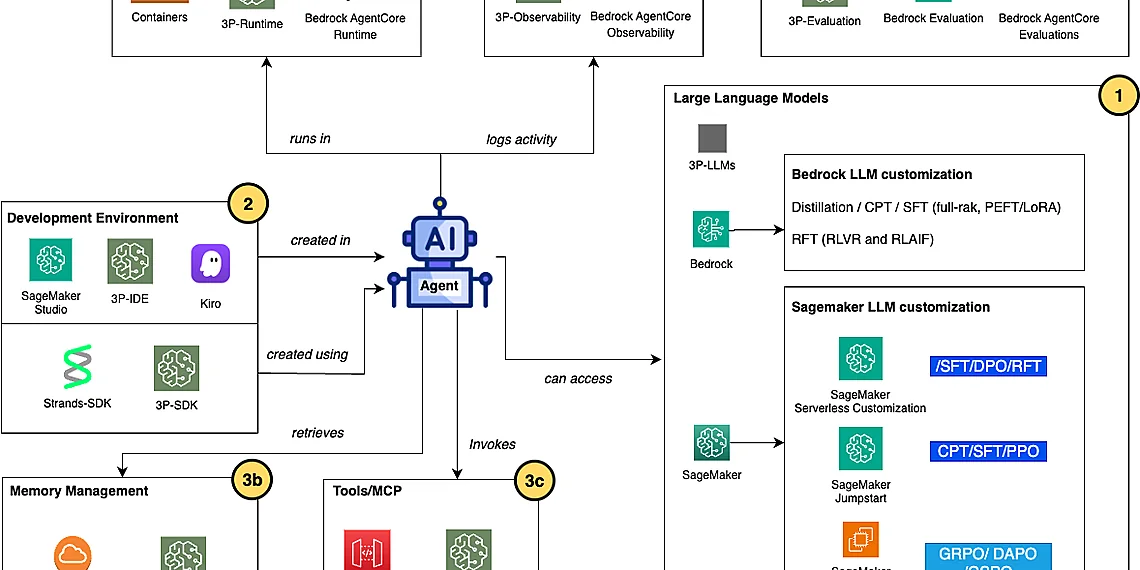
At the base of Amazon’s fine-tuning hierarchy lie established approaches like Supervised Fine-Tuning (SFT), often referred to as instruction tuning, and Proximal Policy Optimization (PPO). SFT involves training an LLM on a curated dataset of input prompts paired with desired output responses. This allows the model to mimic specific behaviors or learn particular styles. PPO, on the other hand, is a reinforcement learning technique that optimizes the model’s policy – essentially, how it makes decisions – by rewarding desirable actions and penalizing undesirable ones. While both SFT and PPO have proven valuable, they can struggle with complex agentic tasks requiring nuanced reasoning or precise alignment with human preferences.
Recognizing these limitations, Amazon’s AI teams have pioneered more sophisticated techniques focused on aligning models with human feedback and enhancing reasoning capabilities. Direct Preference Optimization (DPO) directly optimizes a model based on pairwise comparisons of outputs, bypassing the need for explicit reward functions – simplifying the training process while improving alignment. Building upon this foundation, cutting-edge approaches like Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO) are specifically designed to address the unique challenges of AI agent orchestration. These methods enable more efficient training of complex policies and facilitate the development of agents capable of sophisticated planning and decision-making.
Ultimately, Amazon’s fine-tuning strategies demonstrate a commitment to continuous improvement and innovation in AI agent technology. By systematically advancing from foundational techniques to these groundbreaking optimizations – all while prioritizing human alignment and real-world impact – they’ve unlocked significant performance gains across diverse applications. This iterative process highlights the critical role of tailored fine-tuning in realizing the full potential of AI agents for solving complex problems and driving operational efficiency.
Foundational Methods: SFT & PPO
Supervised Fine-Tuning (SFT), often referred to as instruction tuning, represents a crucial initial step in adapting large language models (LLMs) for specific agentic tasks. This process involves training the pre-trained LLM on a dataset of labeled examples – input prompts paired with desired output responses. Essentially, SFT guides the model to mimic human behavior and follow instructions more effectively than it could based solely on its initial pre-training data. While straightforward to implement, SFT’s effectiveness is limited by the quality and diversity of the training data; a biased or narrow dataset can lead to models that perform well only within restricted scenarios.
Proximal Policy Optimization (PPO) builds upon SFT by introducing reinforcement learning principles. Unlike SFT which relies on static labeled data, PPO allows an agent to learn through interaction with an environment and feedback signals – often in the form of rewards. The algorithm iteratively refines its ‘policy’ (how it acts), aiming to maximize cumulative reward while ensuring that policy updates remain close to the previous policy. This constraint prevents drastic changes that could destabilize training and degrade performance. However, PPO can be computationally expensive for complex agentic environments with large action spaces, and careful reward engineering is critical to avoid unintended behaviors.
In the context of AI agents, both SFT and PPO face challenges beyond those encountered in simpler LLM applications. Agents often require long-term planning, tool use, and interaction with dynamic environments, necessitating more sophisticated fine-tuning approaches than these foundational methods alone can provide. While SFT establishes a baseline for instruction following, and PPO enables learning from experience, advanced techniques like Direct Preference Optimization (DPO) and Group Sequence Policy Optimization (GSPO), discussed later in this article, are increasingly necessary to achieve the robust performance required for real-world agentic impact.
Advanced Optimization for Agent Alignment
Beyond foundational fine-tuning methods like Supervised Fine-Tuning (SFT) and Proximal Policy Optimization (PPO), advanced optimization strategies are crucial for achieving true AI Agent Orchestration – ensuring agents not only perform tasks but also align with human values and exhibit sophisticated reasoning capabilities. This is where techniques like Direct Preference Optimization (DPO) emerge as game-changers. DPO simplifies the reinforcement learning process by directly optimizing a language model to match human preferences, bypassing the complexities of reward modeling often associated with traditional RL methods. It allows for more efficient training with less data, making it particularly attractive for scaling AI agent deployments across diverse applications.
To further enhance reasoning and performance in complex agentic systems, researchers have developed Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO). GRPO addresses the challenges of training large models by grouping parameters during optimization, leading to faster convergence and reduced memory requirements. DAPO focuses on improving policy updates by directly incorporating advantage estimation, resulting in more stable and efficient learning. GSPO builds upon this by optimizing sequences of actions, enabling agents to handle tasks requiring complex planning and decision-making – a key requirement for truly autonomous AI agents.
However, these advanced optimization techniques aren’t without their complexities. GRPO, while offering speed advantages, requires careful consideration of group structure to avoid hindering performance. DAPO’s reliance on accurate advantage estimation demands robust training data and potentially more intricate implementation. GSPO introduces challenges in managing long-range dependencies within sequences, requiring sophisticated architectural designs or specialized training strategies. Understanding these trade-offs is essential for practitioners seeking to leverage these methods effectively in their AI agent orchestration workflows.
The benefits of incorporating such advanced fine-tuning strategies are demonstrable: Amazon Pharmacy saw a 33% reduction in dangerous medication errors, while Amazon Global Engineering Services achieved an impressive 80% reduction in human effort. Content quality assessments also experienced remarkable improvements, jumping from 77% to 96% accuracy. These real-world examples highlight the transformative potential of AI Agent Orchestration and underscore why continued innovation in fine-tuning techniques is critical for unlocking the full capabilities of AI agents.
DPO & Reasoning Optimizations
Direct Preference Optimization (DPO) offers a streamlined approach to aligning language models with human preferences. Unlike traditional Reinforcement Learning from Human Feedback (RLHF), which involves complex reward modeling, DPO directly optimizes the policy based on pairwise preference comparisons – showing the model two responses and asking humans to choose the better one. This bypasses the need for explicit reward functions, simplifying training and improving stability while still effectively guiding the model towards desired behaviors in agentic systems by learning from human feedback without the complexities of a reward model.
For tackling intricate reasoning tasks within AI agents, several advanced optimization techniques have emerged. Grouped-based Reinforcement Learning from Policy Optimization (GRPO) improves sample efficiency by grouping similar actions together during training, allowing for faster convergence and more effective exploration in complex environments. Direct Advantage Policy Optimization (DAPO) builds upon PPO to directly optimize the advantage function, leading to improved performance on tasks requiring sequential decision making. Finally, Group Sequence Policy Optimization (GSPO) extends GSPO further by optimizing entire sequences of actions simultaneously, which is particularly valuable for agents needing to plan and execute multi-step strategies.
These reasoning optimizations – GRPO, DAPO, and GSPO – are crucial for enhancing the capabilities of AI agents in real-world scenarios. They enable more efficient learning, improved exploration, and better performance on complex tasks that require careful planning and execution. By tackling challenges related to sample efficiency, policy stability, and sequential decision making, these methods contribute significantly to building robust and reliable agentic systems capable of achieving increasingly sophisticated goals.
Real-World Impact & Future Directions
The tangible benefits of fine-tuning AI agents are already becoming apparent across Amazon’s diverse operations. Consider Amazon Pharmacy, where targeted fine-tuning led to a remarkable 33% reduction in dangerous medication errors – a critical improvement impacting patient safety and trust. Similarly, within Amazon Global Engineering Services, these techniques have driven an impressive 80% reduction in manual effort for engineers, freeing up valuable time for innovation and strategic initiatives. Finally, the A+ Content team has witnessed a dramatic leap in quality assessment accuracy, jumping from 77% to an astonishing 96%, ensuring consistently high-quality product descriptions and enhanced customer experiences – all thanks to rigorous fine-tuning processes.
These successes highlight the power of techniques like Supervised Fine-Tuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). SFT, or instruction tuning, provides a foundational layer for guiding agents towards desired behaviors. PPO refines those behaviors through iterative policy adjustments, while DPO focuses on aligning agent responses with human preferences, ensuring they are helpful, harmless, and honest. The advancements don’t stop there; Amazon is also exploring cutting-edge reasoning optimizations like Grouped-based Reinforcement Learning from Policy Optimization (GRPO), Direct Advantage Policy Optimization (DAPO), and Group Sequence Policy Optimization (GSPO) specifically designed to enhance the capabilities of complex agentic systems.
Looking ahead, the future of AI Agent Orchestration promises even more sophisticated multi-agent interactions. We can anticipate a shift towards increasingly autonomous agents capable of dynamically adapting to changing circumstances and collaborating seamlessly on intricate tasks. This will likely involve advancements in areas like self-play training – where agents learn from each other through simulated environments – and meta-learning, which allows agents to rapidly adapt to new tasks with minimal fine-tuning. The ability to build ‘agent teams’ that leverage diverse skill sets and reasoning abilities represents a significant frontier for future research and development.
Ultimately, the ongoing evolution of AI Agent Orchestration will be driven by the need to create systems that are not only powerful but also reliable, safe, and aligned with human values. Further refinements in areas like explainability – making agent decision-making processes more transparent – and robustness – ensuring agents perform consistently well even under unexpected conditions – will be crucial for widespread adoption and realizing the full potential of this transformative technology.
Case Studies: Pharmacy, Engineering, A+ Content
Amazon Pharmacy successfully leveraged fine-tuned AI agents to significantly reduce medication errors. By implementing Supervised Fine-Tuning (SFT) focused on instruction tuning, the pharmacy saw a remarkable 33% decrease in dangerous medication errors. This improvement directly enhances patient safety and operational efficiency within their prescription fulfillment process.
The Global Engineering Services team at Amazon achieved substantial gains through AI agent orchestration. Utilizing fine-tuning techniques, they were able to reduce human effort required for various engineering tasks by an impressive 80%. This translates to significant cost savings and allows engineers to focus on more strategic initiatives.
In the realm of content creation, specifically for A+ product descriptions, Amazon employed fine-tuned AI agents to improve quality assessments. Through these targeted adjustments, the accuracy of assessing content quality jumped from 77% to a highly reliable 96%. This ensures that customers receive high-quality, engaging product information.
The journey of scaling AI agents from promising prototypes to impactful real-world solutions demands a relentless focus on fine-tuning, as we’ve seen throughout this exploration.
Successfully deploying these sophisticated systems relies heavily on mastering techniques that allow them to adapt and perform consistently across diverse scenarios – it’s no longer enough to simply build intelligent agents; we must orchestrate their actions strategically.
The future holds exciting possibilities including more robust frameworks for AI Agent Orchestration, enabling complex workflows with greater efficiency and resilience, alongside the rise of personalized agent experiences tailored to individual user needs.
We’re only scratching the surface of what’s possible when generative AI meets intelligent automation, and continued innovation in fine-tuning methodologies will be critical for unlocking its full potential across industries. To delve deeper into how you can leverage these advancements, we invite you to explore Amazon SageMaker AI – a powerful platform designed to streamline your development process and accelerate your journey towards scalable, impactful AI solutions. Stay informed about the latest breakthroughs in generative AI and prepare to witness even more transformative applications emerge.
Continue reading on ByteTrending:
Discover more tech insights on ByteTrending ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









