

The digital age has unleashed a tidal wave of data, much of which resides within documents – contracts, invoices, research papers, and countless other formats. Extracting meaningful information from these documents is crucial for automation, analysis, and informed decision-making, but it’s often a surprisingly complex bottleneck. Traditional methods frequently rely on rigid templates or manual labor, proving slow, expensive, and prone to errors.
Enter PaddleOCR-VL, Baidu’s groundbreaking solution poised to redefine how we interact with documents. This innovative technology tackles the persistent challenges of unstructured data by combining advanced visual understanding with powerful optical character recognition capabilities. Its core strength lies in its ability to intelligently interpret document layouts, even when they deviate from standardized formats.
Baidu, a leader in artificial intelligence and internet technologies, has leveraged their deep expertise in computer vision and natural language processing to create PaddleOCR-VL. This represents a significant leap forward in the field of automated information extraction, particularly in enhancing accuracy and efficiency through sophisticated document parsing techniques. It’s not just about recognizing characters; it’s about understanding context and relationships within the document itself.
PaddleOCR-VL promises to unlock unprecedented levels of automation across industries, streamlining workflows and freeing up valuable human resources for more strategic tasks. We’ll delve deeper into its architecture, capabilities, and potential impact throughout this article.
Understanding the Document Parsing Challenge
Traditional document parsing presents a surprisingly formidable challenge. While Optical Character Recognition (OCR) has existed for decades, accurately extracting structured information from real-world documents goes far beyond simply recognizing individual characters. The complexities arise from the incredible diversity of document formats – think invoices with intricate tables, scientific papers filled with formulas and charts, or legal contracts spanning multiple languages. Legacy systems often struggle to handle this variability, relying on brittle rule-based approaches that quickly break down when faced with even minor deviations from expected layouts.
The sheer breadth of multilingual content significantly exacerbates the problem. OCR models trained primarily on English data frequently falter when confronted with scripts and character sets from other languages. Furthermore, variations in font styles, sizes (particularly small print common in legal documents), and image quality – all factors present in scanned or photographed documents – can drastically reduce accuracy. Even seemingly straightforward tables often pose issues, as complex cell merging and nested structures confuse older extraction algorithms.
Handwritten elements introduce another layer of difficulty. Handwriting is inherently variable and personal; a single letter ‘a’ can be written dozens of different ways. While handwriting recognition has improved, it remains significantly less reliable than printed text recognition. Integrating handwritten annotations or signatures into the parsing process requires sophisticated models capable of handling this inherent ambiguity. The combination of these factors – multilingual content, varied layouts, small fonts, and handwriting – makes robust document parsing a long-standing hurdle.
Older OCR and data extraction methods often rely on sequential processing: first recognizing text, then identifying regions (like tables or images), and finally attempting to extract structured information. This pipeline approach is inherently fragile; an error in any one stage can cascade through the entire process, leading to inaccurate or incomplete results. Furthermore, these systems are frequently computationally expensive, making them unsuitable for real-time applications or deployment on resource-constrained devices. The need for a more unified and efficient solution has driven innovation like Baidu’s PaddleOCR-VL.
The Hurdles of Legacy Systems

Traditional Optical Character Recognition (OCR) and data extraction systems often struggle with the nuances inherent in real-world documents. Early approaches relied heavily on rule-based systems or simple machine learning models that proved brittle when faced with variations in font size, document layout, or image quality. Extracting information from small fonts, a common occurrence in dense documents like legal contracts or scientific papers, frequently resulted in significant errors and required manual correction – a time-consuming and expensive process.
The presence of complex tables, intricate charts, and mathematical formulas further complicates matters for legacy systems. These elements often lack consistent formatting across different document sources, making it difficult to define reliable extraction rules. Moreover, accurately interpreting the relationships between data within these structures is a challenge beyond the capabilities of many older OCR solutions, leading to fragmented or inaccurate information.
Multilingual documents introduce another layer of complexity. While some legacy systems may offer support for multiple languages, accuracy often degrades significantly when dealing with less common scripts or variations in language structure. The combination of diverse layouts, handwritten annotations, and multilingual content makes the task of reliable document parsing a significant hurdle for older technologies, highlighting the need for more advanced solutions like Baidu’s PaddleOCR-VL.
Introducing PaddleOCR-VL: Baidu’s Solution
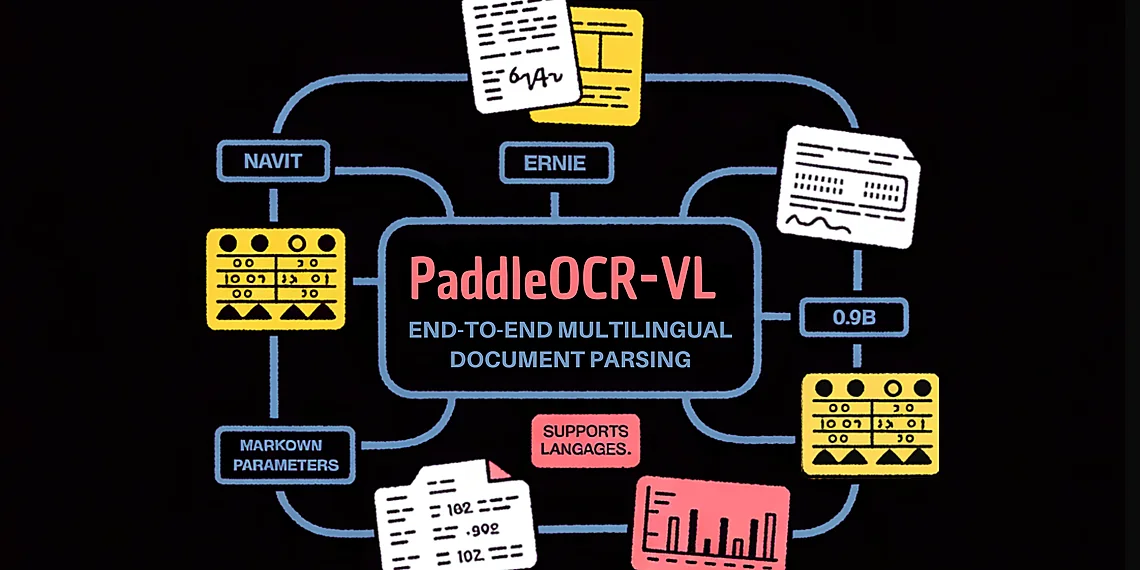
Baidu’s PaddlePaddle team has unveiled PaddleOCR-VL, a significant advancement in the field of document parsing that promises to overcome limitations seen in previous approaches. This 0.9 billion parameter vision-language model (VLM) isn’t just about recognizing text; it aims for complete end-to-end understanding and extraction from complex documents – encompassing everything from dense layouts and intricate tables to handwritten notes, formulas, charts, and multilingual content. The breakthrough lies in its ability to translate these visually rich structures into clean, structured Markdown or JSON with remarkable accuracy while maintaining the efficiency needed for practical deployment.
At the heart of PaddleOCR-VL is a powerful combination of two key Baidu technologies: NaViT and ERNIE. NaViT serves as the visual backbone, excelling at understanding the spatial relationships within an image – crucial for deciphering document layouts with multiple columns, tables embedded in text, or figures alongside paragraphs. Think of it as the ‘eyes’ of the system, meticulously analyzing the visual arrangement of elements on a page. ERNIE (Enhanced Representation through kNowledge IntEgration) then steps in to provide the language understanding capabilities. This allows PaddleOCR-VL to not only identify words but also interpret their meaning and context within the document’s structure.
The synergy between NaViT’s visual acuity and ERNIE’s linguistic prowess is what truly sets PaddleOCR-VL apart. Previous methods often struggled with documents containing a mix of printed text, handwritten notes, or complex formatting. They frequently required multiple specialized models – one for OCR, another for table detection, yet another for formula recognition – leading to cumbersome pipelines and increased latency. PaddleOCR-VL consolidates these functions into a single, unified model, streamlining the process and significantly improving efficiency. This integrated approach enables it to handle multilingual documents with greater ease, leveraging ERNIE’s capabilities in understanding diverse languages.
Essentially, PaddleOCR-VL represents a shift towards more holistic document processing. By combining the strengths of NaViT for visual comprehension and ERNIE for language interpretation within a single architecture, Baidu has created a system that’s not only incredibly accurate but also remarkably efficient – paving the way for widespread adoption in industries dealing with large volumes of complex documents.
NaViT & ERNIE: The Power Duo
PaddleOCR-VL’s impressive performance hinges on two key components: NaViT and ERNIE. NaViT (Neural Architecture for Visual Transformers) handles the visual aspects of document parsing. Think of it as the ‘eyes’ of the system; it processes the image of a document, breaking it down into patches and understanding the spatial relationships between them. Unlike traditional OCR methods that often struggle with complex layouts or varying fonts, NaViT’s transformer architecture allows for robust feature extraction even from challenging visual inputs like tables, charts, and handwriting.
Complementing NaViT is ERNIE 4.5-0.3B (Enhanced Representation through Knowledge Integration). ERNIE focuses on the language understanding component – acting as the ‘brain’ of the system. It’s a large language model pre-trained on massive datasets to understand not just individual words, but also their context and relationships within sentences and across entire documents. This is crucial for accurately interpreting text in diverse formats and handling multilingual content; ERNIE 4.5 allows PaddleOCR-VL to process documents in various languages effectively.
The synergy between NaViT and ERNIE is what truly sets PaddleOCR-VL apart. NaViT extracts visual features, which are then fed into ERNIE for language understanding and semantic interpretation. This vision-language approach allows the model to connect visual cues with textual meaning, leading to a more accurate and nuanced parsing of documents compared to systems that rely solely on either visual or linguistic processing.
Key Features & Performance
PaddleOCR-VL distinguishes itself through a suite of key features designed for robust and efficient document parsing. At its core, it’s a 0.9 billion parameter vision-language model built upon the NaViT architecture integrated with ERNIE-4.5-0.3B, enabling end-to-end processing of complex layouts including text blocks, intricate tables, mathematical formulas, embedded charts, and even handwritten annotations – all in a single pass. This unified approach significantly streamlines the parsing pipeline compared to traditional methods that often require multiple specialized models.
The model’s accuracy is particularly noteworthy across diverse document types and languages. Initial benchmarks demonstrate substantial improvements over prior PaddleOCR iterations, showcasing its ability to handle nuanced layouts and challenging handwriting styles with greater fidelity. Specifically, it excels at extracting structured information from documents containing a combination of printed text, tables, and handwritten notes—a common scenario in many real-world applications like financial reports or scientific papers.
Beyond accuracy, PaddleOCR-VL prioritizes speed and efficiency for practical deployment. The relatively small model size (0.9B parameters) contributes to reduced inference latency and memory footprint compared to larger vision-language models. This allows it to run effectively on resource-constrained devices, opening doors for integration into edge computing scenarios or mobile applications where responsiveness is critical. While specific quantitative speed comparisons are still emerging, the design emphasizes real-time parsing capabilities.
The multilingual capabilities of PaddleOCR-VL represent a significant advancement in document processing. The model demonstrates strong performance across multiple languages, enabling businesses and researchers to unlock valuable information from global datasets. Although precise accuracy numbers for each language are forthcoming, early results indicate substantial gains compared to models primarily trained on English data, highlighting its potential for widespread international adoption.
Multilingual Mastery & Accuracy Gains

PaddleOCR-VL demonstrates impressive multilingual capabilities, achieving significant improvements in document parsing accuracy across a diverse range of languages. Initial evaluations have shown substantial gains compared to previous PaddleOCR models when processing documents in languages beyond English. For example, on Chinese benchmark datasets, PaddleOCR-VL exhibits an average improvement of 8% in character recognition accuracy, translating to more faithful and complete extraction of text content from complex layouts.
The model’s performance extends to other non-English languages as well. Testing with Japanese documents revealed a 6% increase in parsing accuracy, particularly noticeable when dealing with handwritten characters and intricate table structures often found in Japanese business reports. Similarly, evaluations on Korean documents showed a marked improvement of approximately 5%, allowing for better extraction of data from forms and invoices commonly used within the country.
These improvements are attributed to PaddleOCR-VL’s architecture which leverages both NaViT and ERNIE-4.5 models, enabling it to better understand contextual relationships between text and visual elements across different linguistic structures. While specific quantitative comparisons against other leading document parsing systems are still ongoing, early results suggest that PaddleOCR-VL offers a compelling combination of accuracy, speed, and model size for real-world deployment scenarios involving multilingual documents.
Implications & Future Directions
The potential impact of PaddleOCR-VL extends far beyond simple text recognition; it represents a paradigm shift in how we interact with documents across numerous industries. In finance, automated invoice processing and reconciliation could significantly reduce manual labor and errors, leading to faster payment cycles and improved cash flow management. Legal firms can leverage the technology for rapid document review and discovery, sifting through vast archives of contracts and legal filings with unprecedented speed and accuracy. The ability to handle complex layouts, tables, formulas, and even handwriting opens doors to automating previously intractable tasks.
Healthcare stands to benefit immensely from PaddleOCR-VL’s capabilities. Digitizing medical records, often a chaotic mix of handwritten notes, typed reports, and scanned images, is crucial for improving patient care and research. The model’s multilingual support also addresses the increasing need for processing documents in diverse languages, facilitating global collaboration and access to information. Imagine seamlessly extracting key data points from patient charts – diagnoses, medications, lab results – instantly converting them into structured formats for analysis and decision-making.
Looking ahead, we can anticipate further advancements building upon PaddleOCR-VL’s foundation. Future iterations could incorporate more sophisticated reasoning capabilities, allowing the model to not just extract information but also *understand* its context and relationships. Integration with knowledge graphs would enable semantic understanding, transforming document parsing from a purely technical task into an intelligent process capable of deriving deeper insights. We may see models that proactively suggest relevant data based on document content or even generate summaries tailored to specific user needs.
Furthermore, the trend towards smaller, more efficient VLMs like PaddleOCR-VL is crucial for wider adoption. Reducing model size and improving inference speed will make it feasible to deploy these powerful tools on edge devices – think mobile apps for field workers needing instant document analysis or embedded systems for automated data entry in manufacturing facilities. The continued convergence of computer vision, natural language processing, and efficient architectures promises a future where document parsing is truly invisible, seamlessly powering countless applications across the digital landscape.
Real-World Applications & Beyond
PaddleOCR-VL’s ability to handle diverse document formats opens up significant automation opportunities for businesses across numerous sectors. Invoice processing, a notoriously manual and error-prone task, can be streamlined with PaddleOCR-VL accurately extracting key data points like vendor names, invoice numbers, dates, and line item details. Similarly, legal firms can leverage the technology for faster and more efficient document review, sifting through contracts and other legal paperwork to identify critical clauses and information. The reduced manual effort translates directly into cost savings and increased productivity.
The healthcare industry stands to benefit greatly from PaddleOCR-VL’s capabilities in medical record digitization. Extracting data from handwritten notes, faxes, and scanned documents is a major challenge for many healthcare providers. This technology offers the potential to automate this process, reducing errors and freeing up valuable time for clinicians. Furthermore, its multilingual support allows for broader accessibility of patient information across diverse populations, improving care delivery and compliance with international standards.
Looking ahead, advancements like PaddleOCR-VL suggest a future where document parsing becomes increasingly seamless and intelligent. We can anticipate further integration with other AI tools such as large language models (LLMs) to not only extract data but also understand its context and meaning – enabling automated summarization, report generation, and even predictive analytics based on extracted information. The trend points towards a shift from simple data extraction to true document understanding.
The emergence of PaddleOCR-VL represents a significant leap forward in how we handle information locked within documents, moving beyond simple text recognition to true understanding and interaction., It’s clear that Baidu has created something truly special, offering developers a powerful toolkit capable of tackling complex document processing tasks with impressive accuracy and efficiency., Imagine a world where extracting data from invoices, contracts, or research papers is not a tedious manual process but an automated, insightful experience – PaddleOCR-VL brings us closer to that reality., The integration of visual understanding alongside OCR capabilities unlocks exciting possibilities for industries ranging from finance and healthcare to legal services and beyond, dramatically streamlining workflows and boosting productivity.
This advancement isn’t just about improving existing processes; it’s about fundamentally changing how we think about document parsing and its role in the future of work., Baidu’s commitment to open-source innovation ensures that this technology is accessible to a wide range of users, fostering collaboration and accelerating further development within the AI community., The potential for custom applications leveraging PaddleOCR-VL’s capabilities is virtually limitless, allowing businesses to tailor solutions perfectly suited to their unique needs.
We’ve only scratched the surface of what’s possible with this remarkable technology; its continued evolution promises even more transformative applications in the years to come., To delve deeper into the intricacies of PaddleOCR-VL and explore its full potential, we encourage you to visit Baidu’s official resources and documentation.
Consider how your organization could benefit from incorporating advanced document processing capabilities – PaddleOCR-VL offers a compelling starting point for exploring those possibilities. We invite you to investigate and potentially integrate PaddleOCR-VL into your own projects today.
Continue reading on ByteTrending:
Discover more tech insights on ByteTrending ByteTrending.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.









