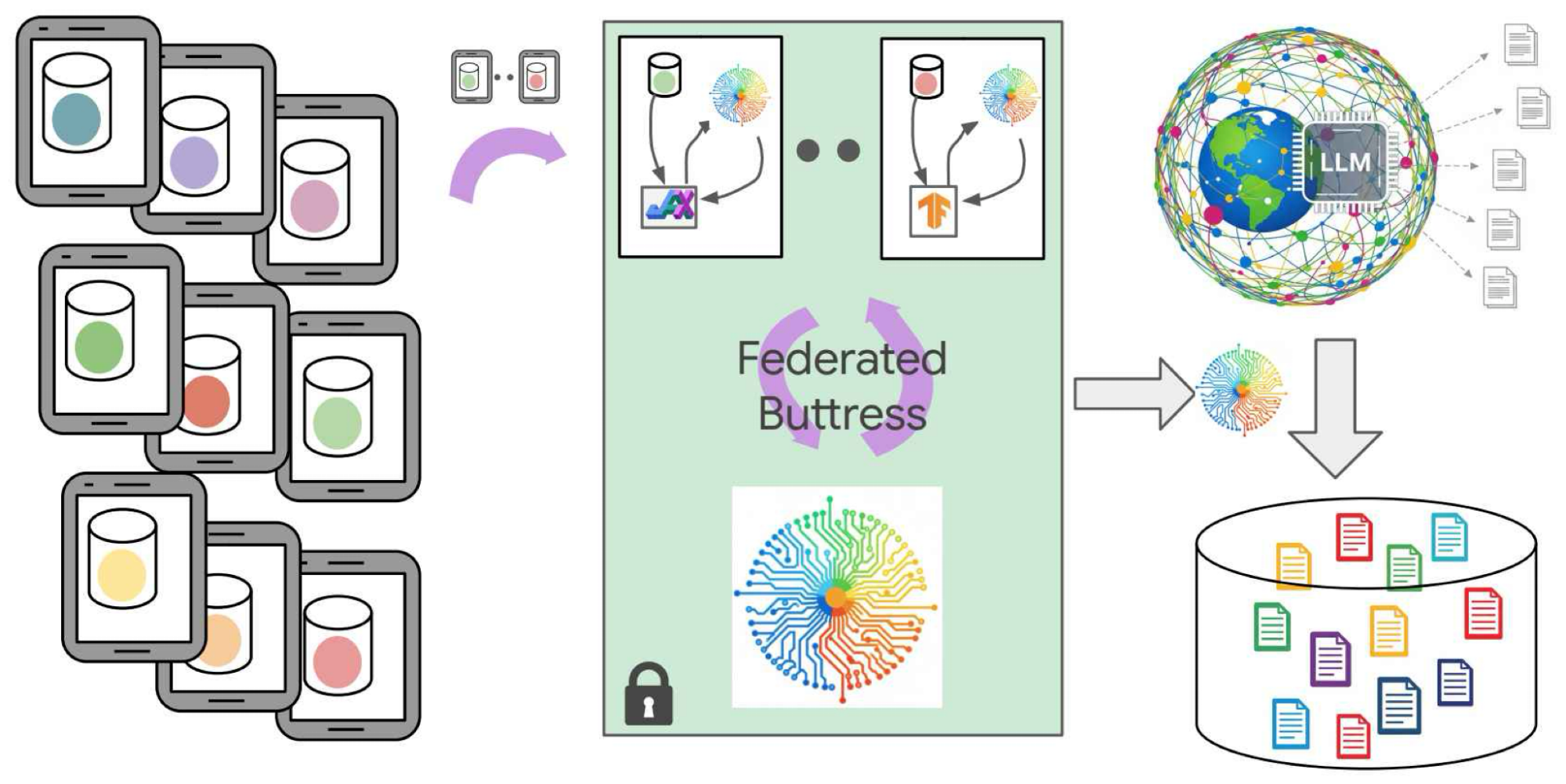
Adapting Mobile Apps Without Compromising User Privacy
What: The Google Research team has developed a novel approach to domain adaptation – the process of training machine learning models on one dataset (the source) and applying them to a different, related dataset (the target) – that prioritizes user privacy. This new technique leverages synthetic data generation alongside federated learning, offering a powerful solution for mobile applications where data sensitivity is paramount.
Why it Matters: Mobile apps rely heavily on machine learning for tasks like personalized recommendations, predictive text input, and image recognition. However, training models directly on user data raises significant privacy concerns. Traditional domain adaptation methods often require access to the target dataset, which can be difficult or impossible to obtain due to privacy regulations and competitive pressures. This new approach addresses these challenges head-on.
Synthetic Data Generation with Large Language Models (LLMs)
The core of this innovation lies in using large language models (LLMs) – like PaLM 2 – to generate synthetic data that mimics the characteristics of the target dataset. Here’s how it works:
- Understanding the Target: The LLM first analyzes the target dataset, learning its underlying patterns and distributions. This involves understanding user behavior, application usage, or whatever specific domain adaptation is needed.
- Generating Realistic Data: The LLM then generates new data points that statistically resemble the original target data. Crucially, this synthetic data doesn’t contain any real user information – it’s completely anonymized.
- LLM Fine-tuning: The LLM itself can be fine-tuned on the synthetic data to further improve its ability to accurately mimic the target distribution. This iterative process ensures that the synthetic data is as realistic and useful as possible for training domain adaptation models.
Federated Learning for Enhanced Privacy
Synthetic data generation alone isn’t enough. To truly minimize privacy risks, Google’s approach integrates federated learning. Federated learning allows multiple devices (e.g., mobile phones) to collaboratively train a model without sharing their raw data. Here’s the process:
- Local Training: Each device trains a local model on its own synthetic data.
- Central Aggregation: Only the model updates – not the original data – are sent to a central server for aggregation.
- Global Model Update: The aggregated updates create a new, improved global model that benefits from the collective knowledge of all devices.
This federated training process ensures that user data remains on their devices throughout the entire adaptation workflow. This significantly reduces the risk of data breaches and enhances privacy compliance.
Benefits: This combined approach offers several key advantages:
- Privacy Preservation: No real user data is ever exposed during the domain adaptation process.
- Data Availability: Synthetic data can be generated even when access to the target dataset is limited or unavailable.
- Model Performance: The use of realistic synthetic data, combined with federated learning, leads to high-performing domain adaptation models.
Conclusion: Google’s work demonstrates a promising path towards privacy-preserving domain adaptation for mobile applications. By combining LLM-generated synthetic data with federated learning, developers can unlock the power of machine learning without compromising user privacy – a critical step toward building more trustworthy and responsible AI systems.
Source: Read the original article here.
Discover more from ByteTrending
Subscribe to get the latest posts sent to your email.








